How Celonis Kafka Connector Works
Celonis Kafka Connector takes care of reading and deserializing the data before passing it to the sink code. Any data transformations required can leverage Connect Single Message Transform (SMT), to adjust the data shape before it reaches the sink code.
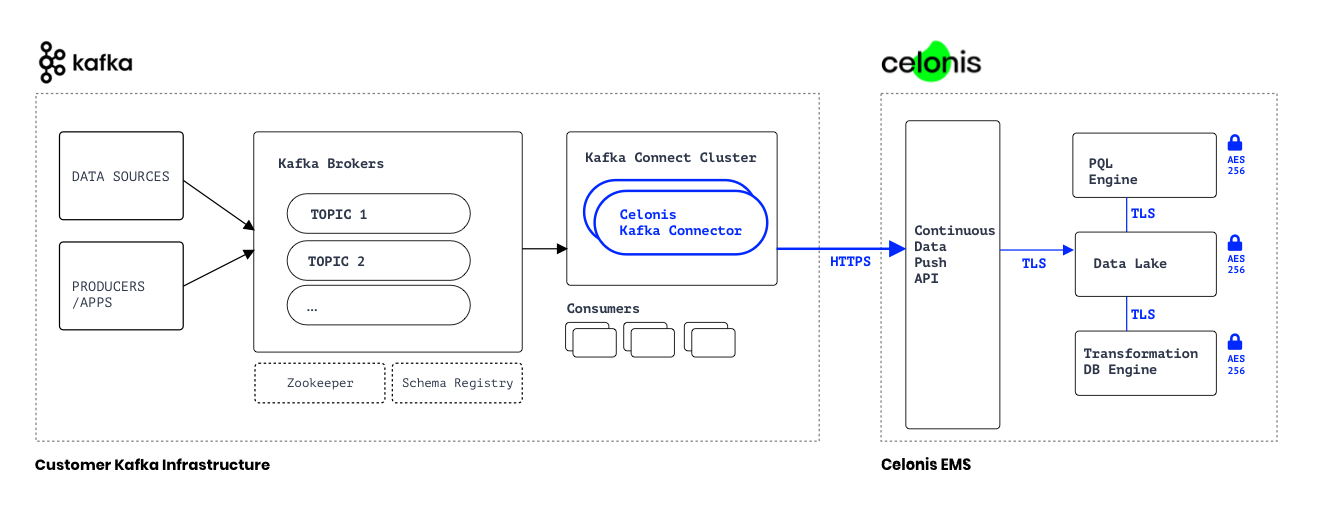
Each Connect sink instance can read from one or more Kafka topics and publish to a given target table. To send data to more than one target, a connector has to be created per target. |
The connector leverages Celonis Platform Continuous Push API. The API requires parquet files to be uploaded. Once in Celonis Platform, the files are processed at a time interval.
A Kafka topic represents a data stream- an infinite sequence of records. To reduce the network chattiness, the sink accumulates files locally for each topic-partition tuple involved. When the accumulated file reaches specified thresholds (size, records, or time), they are uploaded to Celonis Platform. This, of course, introduces latency, a latency that can be tweaked according to the needs. Once the file is uploaded, the process continues, a new file is created, and records are appended.
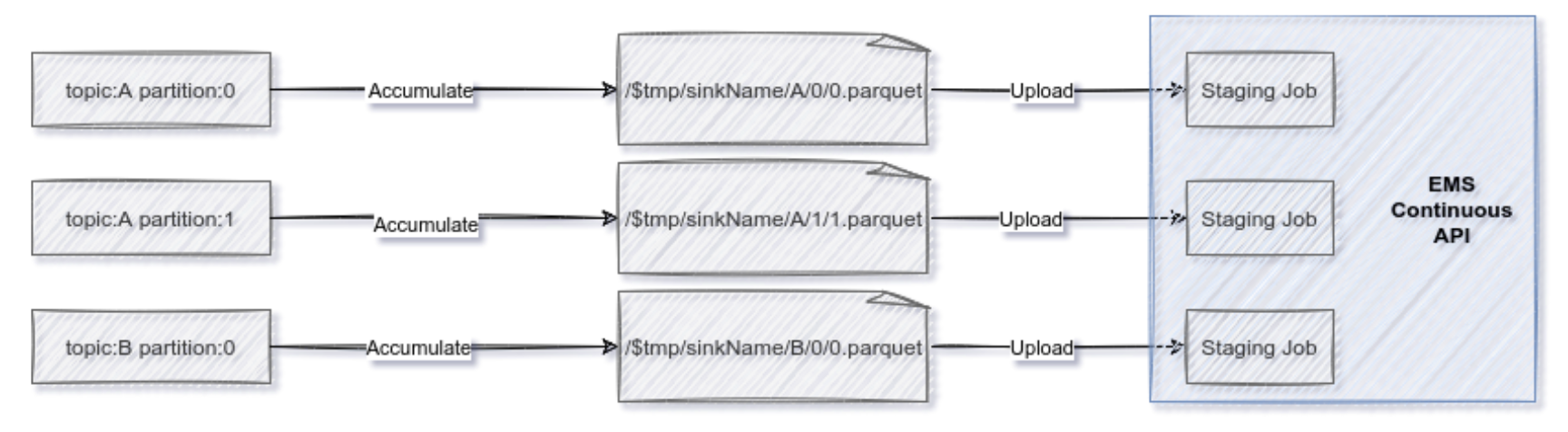
Writing with exactly-once semantics is a challenge given there are writes across systems: uploading the file and committing the Kafka offsets. In Celonis Platform, the data is processed as an UPSERT (An operation that inserts rows into a database table if they do not already exist or updates them if they do). Because of this, the constraints can be relaxed and rely on eventual consistency if a record is uploaded multiple times; the latest record data will be eventually stored.
A file written to Celonis Platform is considered “durable” because, eventually, the data will be processed and made available to the Process Query Language(PQL) engine. The sink code will not check Celonis Platform internal data processing jobs for uploaded files. Because a data job can take, at times, hours to be processed, that does not play well with the continuous flow of data in Kafka and could easily trigger a connector rebalance. One of the main reasons the Celonis Platform internal job will fail is data misalignment: the incoming file data and schema are not aligned with the target table schema. For that, at the moment, there is no error reporting. Future solutions will, however, address this gap.
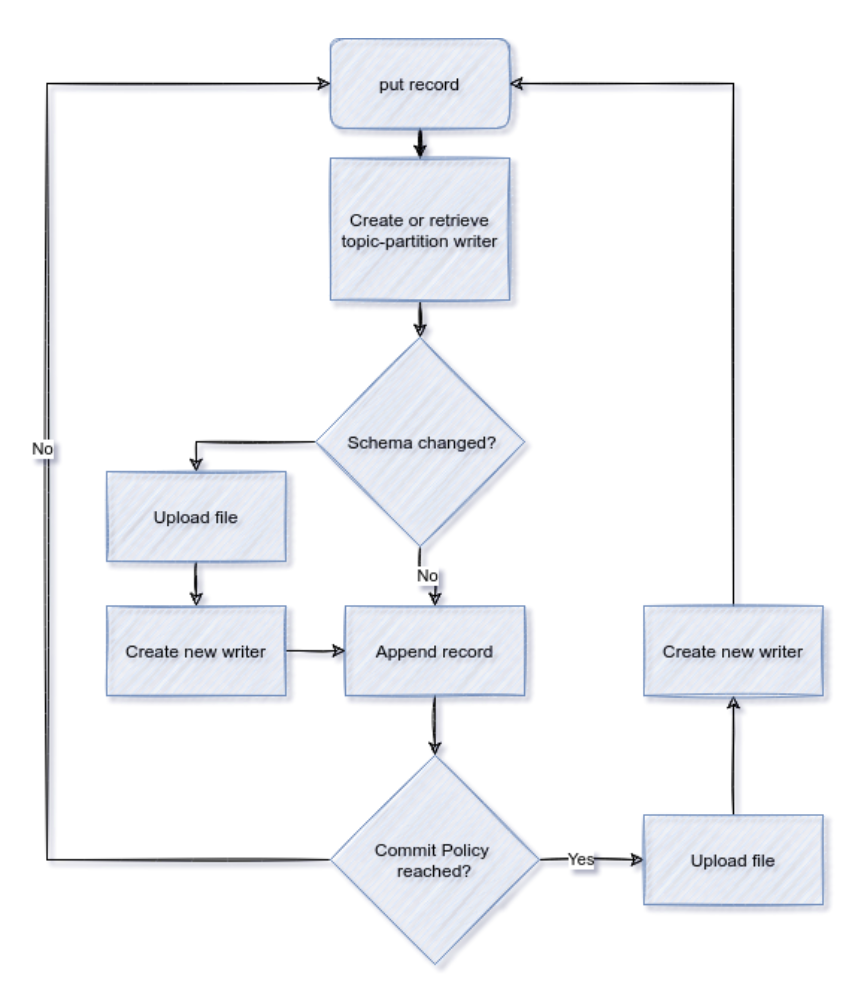
Here is the logical flow for a Kafka message record within the connector: