August 2024 Release Notes
PQL (2024-08-28)
Automatic tailoring of PQL queries using Static PQL checks
You can now write PQL queries that run based on the outcome of one or more data model conditions, such as the data type of a column or the existence of match list elements in comparison operators.
Before your query is run, Static PQL dynamically checks some properties of your data model and modifies or cancels your PQL query depending on the outcome of these checks.
This lets you define business applications that can be used with a range of different data models, helping drive standardization.
Object-centric process mining (2024-08-27)
Create templates for your transformations
You can now set up a template containing an SQL query, and use it to create the transformations for many similar object types or event types. Templates are especially useful if you are modeling multiple flavors of the same event (for example, delivery dispatch by different shipping methods), or if you are transforming data from multiple data sources to create the same objects or events.
When you're creating a transformation for an object type or event type, you'll now get the choice to use one of your transformation templates. There's a new Templates tab in the Transformations area of the Objects and Events environment, where you can create, edit, rename, and delete your transformation templates. You can also see the transformation instances that you've created using each template. The list of transformations in the Transformations tab tells you if a transformation was created from a template, and you can access the template from there too.
To get the best out of transformation templates, include local parameters in them for the parts that you expect to vary, such as the source system name. For each transformation instance that you create from a template, you can then just go to the list of local parameters in the transformation editor, and add the correct values for that transformation. The content from the template remains read-only, and it changes to match if you edit the template - so with one edit you can apply fixes or updates to all the transformations that use the template. If a transformation instance needs further customization, for example because a source system holds the data for an attribute in a different way, you can create a partial overwrite like you would for a Celonis catalog transformation. Partial overwrites stay in effect when the template changes.
Process Adherence Manager (2024-08-27)
Improved visualization of self-loops
We've made it easier to identify self-loops in Process Adherence Manager. The arrow indicating a self-loop now displays in the same color as the event log it appears in. Where a self-loop occurs in more than one event log, an arrow displays for each affected event log in the color of that event log.
Refining and editing your baseline model is also simplified as you can now add and delete individual self-loops, as well as replacing a self-loop with an event suggested by Process Adherence Manager.
Object-centric process mining (2024-08-22)
Automatically handle source system data issues
When you enable a process from the Celonis catalog, you can now choose to skip missing data from your source system. If you enable this feature for a data connection, we'll handle these issues:
If your source system data is missing columns that the Celonis object types and event types require, we'll skip over them. Your objects and events will be created with null values in these fields.
If your source system data has data types for required columns that don't match those expected by the Celonis object types and event types, we'll cast them to match the expected data types, and use that in your objects and events.
You can activate the feature when you create a new connection or at any time afterwards. We’ve disabled it by default for your existing data connections, but you can activate it for them if you need it.
Skipping missing data lets your transformations run with errors, so you can still create objects and events even if your data isn't ideal. It's important to know that applications consuming the objects and events can get unexpected problems from the missing data. We recommend that you only use this feature while you're validating the implementation of a process or app. Soon after that, you should go back and fix the issues in a pre-processing stage or during data extraction.
Oracle Fusion BICC Extractor (2024-08-22)
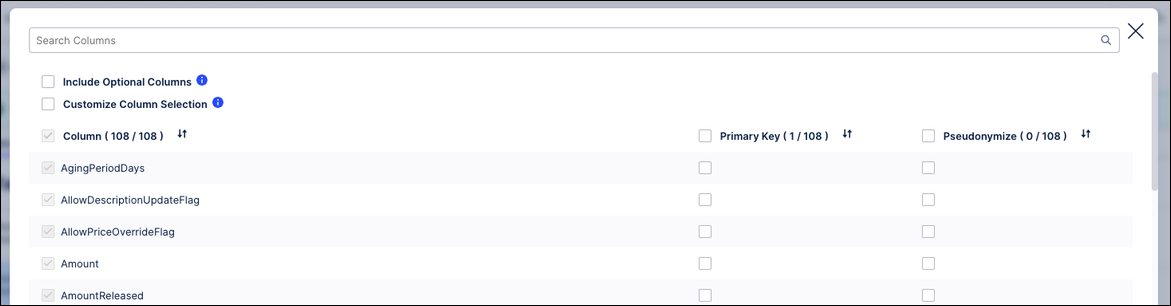
Optionally extract non-populated columns
The Oracle Fusion BICC Extractor didn't previously extract columns marked in the metadata as "isPopulate": false (non-populated columns). You can now choose to extract these as well by selecting the new extraction parameter Include Optional Columns during column configuration. When you do, we'll add the optional columns to the display and include them in the extraction by default. This can add a lot of extra columns, so we recommend you also select Customize Column Selection, then go through the updated list of columns and uncheck any that you don't want for your business case. For the extractor instructions, see Oracle Fusion Cloud BICC.
The BICC Extractor is in Limited Availability status. To get access as an early adopter, ask your Celonis point of contact.
Object-centric process mining (2024-08-21)
Create object types and their transformations from source system tables
Instead of modeling an object type from scratch, you can now choose to create it based on a table in your source system, with columns from the table becoming attributes of the object type. When you use this method, we'll create a preview of the object type where you can select which columns you do and don't want to turn into attributes. You can rename the object and its attributes (by default we use the table and column names). You can also add extra attributes for data in your table or outside it.
When you've finished, we'll create the object type, and you can choose to also have us autogenerate the SQL transformation scripts for it. The autogenerated transformation contains the SQL statements that you'll need to populate the object type’s attributes with the data from your source system table. You'll need to add SQL statements to identify the object ID, and to populate any extra attributes that use data from somewhere other than your original source system table. Then your object type is ready for you to create its relationships to other objects and to events as part of your object-centric data model.
Object-centric process mining (2024-08-20)
Extend Celonis event types with attributes and relationships
You can now add custom attributes to event types from the Celonis catalog, and create custom event to object relationships using them. The event to object relationships can be to custom object types or to object types from the Celonis catalog. So you can now leverage both the ready-made object types and event types to create customized processes.
If you've already created custom event types to replace Celonis event types, consider customizing the equivalent Celonis event types instead. Using the Celonis object types and event types means you don’t need to reproduce attributes, relationships, and transformations that we already created. It also means you'll stay up to date with the requirements for the Celonis apps and features that are built to use our standard objects and events. You can customize app views and logic to incorporate your custom attributes and relationships. Or if you don't need them for an app, they won't cause a problem, the app will just ignore them.
Data integration (2024-08-20)
Removal of SAP on-premise extraction (OPE) client
We removed the SAP on-premise extraction client from the Celonis Platform Download Portal on 2024-08-20. While any OPE instances that are already in use are unaffected, you now won't be able to set up a new SAP extractor or upgrade any existing SAP extractors.
From 2024-08-20, you should use our on-premise client (OPC) instead. For information about accessing the OPC, see Installing on-prem clients.
For information about the benefits of using OPC, see On-premises clients (OPC).
RFC Module 3.9 (2024 August)
With the 3.9 version of the RFC Module, there's no need to create a directory on the SAP file system to store extracted data temporarily. The new extractor uses a staging table within the SAP application database for this purpose. This updated architecture offers a simplified setup and improved reliability. For more information, see RFC module.
Studio (2024-08-19)
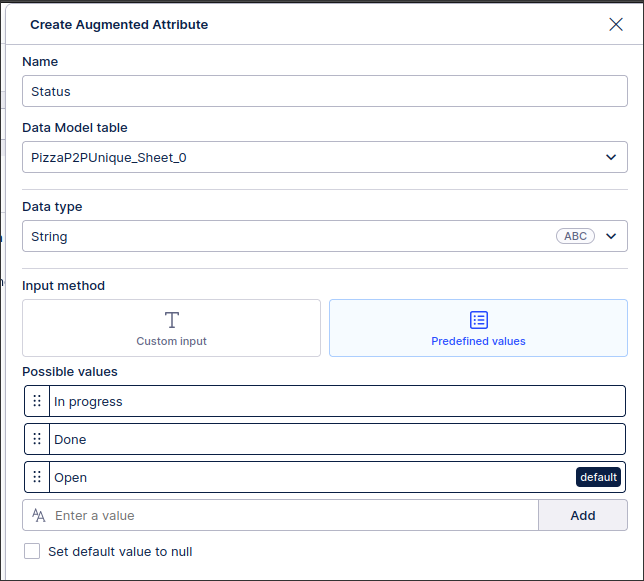
Improved augmented attribute creation flow
We've improved our augmented attribute creation flow, making it easier to select and configure different data types.
Augmented attributes are a Knowledge Model (KM) asset that can be updated in real-time and without the Data Model reloading. By assigning an augmented attribute to a specific table in the Data Model, you can add additional information to the source system. This additional information can then be referenced in your Views, describing your business objects in further detail and generating additional process insights.
To learn more about creating and using augmented attributes in your Studio content, see: Augmented attributes.
 |
Data Integration (2024-08-19)
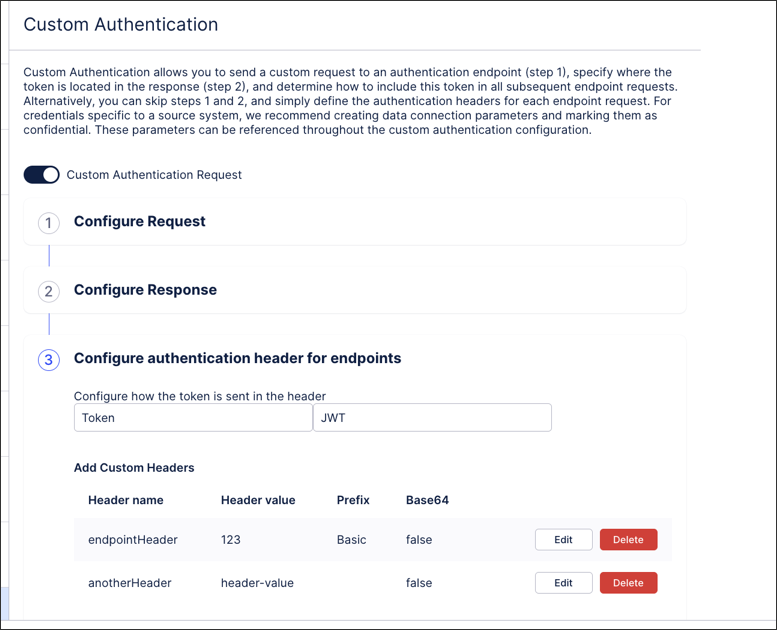
Custom authentication method using extractor builder
You can now configure a custom authentication method when creating a connection between your source system and the Celonis Platform using the extractor builder. The custom authentication type allows you to configure the authentication method based on your source system. This includes the following configurations:
Request (optional): Configure an API request to an authentication endpoint with all details (Request Type, Request URL, Headers, Parameters etc.)
Response (optional): Configure the location of an authentication token in the API response.
Authentication header: Configure how the response token is used in the authentication header for all endpoint request and add additional headers on top.
For more information about the extractor builder, see: Extractor Builder.
And for an overview of authentication methods, see: Extractor Builder authentication methods.
 |
Transformation Hub (2024-08-05)
Analyst access added to Transformation Hub
Users with an Admin role in a team can now give Analyst users within that team access to Transformation Hub using permissions.
For information on assigning permissions, see Transformation Center permissions.
Object-centric process mining (2024-08-05)
Control Celonis catalog updates
At the moment, when we release a new version of the Celonis catalog with upgraded object types, event types, relationships, transformations, and perspectives, we apply the update automatically in your team. This includes Celonis catalog items in processes that you've already enabled and used in your object-centric data model, which might get behavior changes or new attributes.
It's important to keep your Celonis catalog items up to date because downstream consumers such as our Business Apps are always based on the latest version of the object types and event types in the Celonis catalog. You also need to keep the SQL transformations up to date so that they are compatible with the current requirements for the object-centric data model - out of date transformations might result in errors when you try to save and publish your model. But there's always times when you're in the middle of something important and you don't want an update right now. So from 31 July, you'll be able to choose when to apply a new Celonis catalog update in your team.
When a new version of the catalog is available, we'll display an Update available link on the Objects and Events dashboard next to the current catalog version, and an Update button on the catalog view. Click the button to get a link to the release notes, and read what's changed in this update and in any previous updates that you skipped. Then select Update catalog if you want to go ahead with the update, or Cancel if you don't want to update now. You'll still have the option available to update when you're ready.
Partitioned Extractions for SAP (2024-08-01)
Important
This functionality is in General Availability for SAP. For all other connectors, it is in Limited Availability. If you’d like to try it out, please contact us through celopeers.com/s/support.
Data from large tables can now be extracted in chunks to reduce the extraction time and limit the chances of failure which can happen when extracting high data volumes. Once extracted, such chunks are merged into a single table in Celonis Platform and function the same way as tables extracted in full. For more information, see Enabling partitioned extractions of large tables.