MERGE_EVENTLOG - MERGE_EVENTLOG_DISTINCT
Description
MERGE_EVENTLOG merges two columns of the same type from two activity tables into one common column. The sorting of entries in the resulting column is based on timestamps and, if specified, the sorting column, according to Activity table sorting. Depending on the join scenario, the result of MERGE_EVENTLOG might contain some duplicated activities. If this is not desired, then MERGE_EVENTLOG_DISTINCT can be used. Please note that MERGE_EVENTLOG and MERGE_EVENTLOG_DISTINCT only differ regarding duplicated activities and otherwise behave the same.
Given two columns of the same type from two activity tables whose case tables are connected directly or indirectly, the MERGE_EVENTLOG operator computes one common (internal) table, containing the merged result of the two input columns. In general, there are two scenarios how the activity tables can be linked in the data model. The following section describes these two scenarios. Thereby, the direction of the merge is defined by the order of the input columns. The first column is the target column, the second column is the source column. The content of the source column is always merged into the corresponding cases of the target input column. Hence, the target cases will be enhanced with the entries of the source column.
This means that only cases that exist in the case table of the target column will be in the resulting eventlog table.
The resulting (internal) table is joined to the case table of the first input column.
1:n Scenario
Given two activity tables whose case tables are connected directly or indirectly via a 1:n relationship, MERGE_EVENTLOG computes one combined (internal) table ('Merge Table') sorted by timestamp. The resulting table is always joined to the case table of the first input column. If the first input column is e.g. from 'Activity Table 1', the resulting 'Merge Table' is joined to 'Case Table 1'.
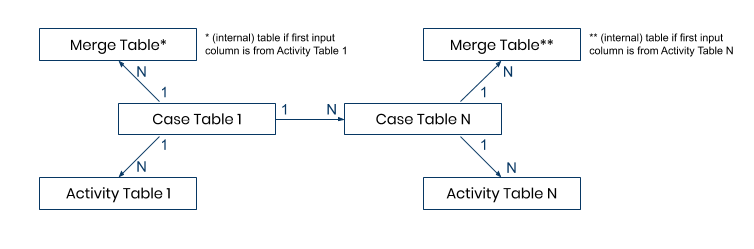
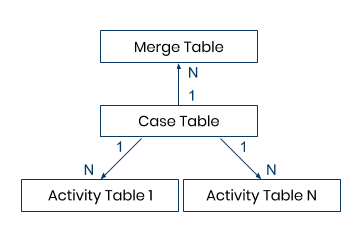
The two activity tables can also share one case table like shown in the following picture.
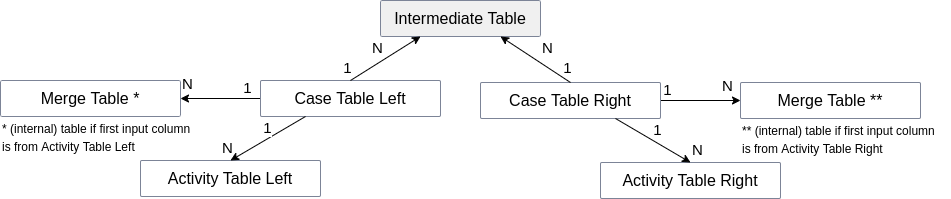
n:m and n:1:m Scenario
In case of a n:m or a n:1:m scenario,the join from 'Case Table Left' to 'Case Table Right' over the intermediate tables is calculated transitively. MERGE_EVENTLOG computes one combined (internal) table that is joined to the case table of the first input column. In the following examples, two activity tables 'Activity Table Left' and 'Activity Table Right' and their corresponding case tables 'Case Table Left' and 'Case Table Right' are given.
n:m Example
The case tables have a n:m relationship, which is modeled via two 1:n relationships and an intermediate table 'Intermediate Table'. The table created by MERGE_EVENTLOG is joined to the case table of the first input column. If the first input column is e.g. from 'Activity Table Left', the resulting (internal) 'Merge Table' is joined to 'Case Table Left'.
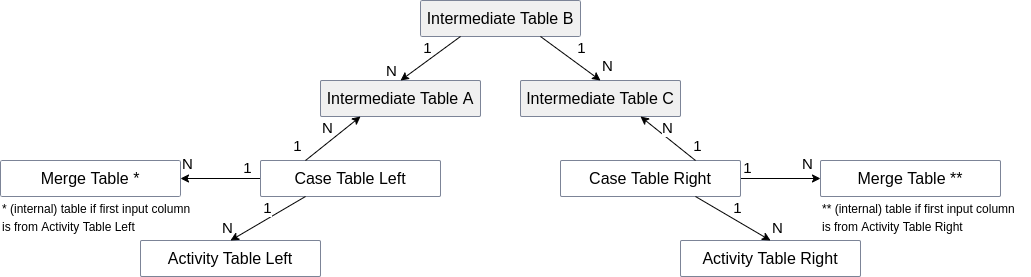
n:1:m Example
The case tables have a n:1:m scenario, which is modeled via two 1:n relationships and three intermediate tables 'Intermediate Table A', 'Intermediate Table B' and 'Intermediate Table C'. If the first input column is e.g. from 'Activity Table Left', the resulting (internal) 'Merge Table' is joined to 'Case Table Left'.
Syntax
MERGE_EVENTLOG ( target_table.column [, FILTER target_table_filter_expression ] , source_table.column [, FILTER source_table_filter_expression ] )
MERGE_EVENTLOG_DISTINCT ( target_table.column [, FILTER target_table_filter_expression ] , source_table.column [, FILTER source_table_filter_expression ] )
target_table.column: A column of an activity table.
target_table_filter_expression (optional): An optional filter expression to specify which rows of the target_table should be taken into account for the resulting merged eventlog.
source_table.column: A column of an activity table.
source_table_filter_expression (optional): An optional filter expression to specify which rows of the source_table should be taken into account for the resulting merged eventlog.
NULL handling
If there is no corresponding entry for a case in the case table, this case will be ignored.
If in the mapping of the cases the source case id is NULL, the target case will still be in the result table.
If the value of the case column of a row is NULL, the row will be ignored.
If the value of the timestamp column is NULL, the row will be ignored.
If the value of an activity column is NULL, the row will be ignored.
Limitations
The current limitations documented in Engine Limitations also hold for the result of MERGE_EVENTLOG. This means that the hard upper limit of rows for the result column of MERGE_EVENTLOG is 2.1 billion rows, and the recommended limit of rows is 800 million rows.
Special cases
Activities, that do not have a corresponding case id in the case table are not taken into account.
If an activity of the target table has a join partner in the source table but its case id is not in the target case table, the mapped activities are not taken into account.
If an activity of the source table has a join partner in the target table but its case id is not in the source case table, the target activity is in the resulting merged eventlog but the activities of the source table are ignored.
If there is a case id in the target case table but no corresponding activity in the target table and there is a join partner in the source table, the case id for for the merged activities from the source table will be generated. See section "Case ID Generation" for more information.
Peculiarities
The three required columns of every activity table (CaseID, Activity, Timestamp) are always implicitly merged in the background. Therefore, they can be referenced from any
MERGE_EVENTLOGresult using the CASE_ID_COLUMN, ACTIVITY_COLUMN and TIMESTAMP_COLUMN reference functions. It is also possible to automatically reference the corresponding case table of theMERGE_EVENTLOGresult using the CASE_TABLE function.MERGE_EVENTLOGis used for the automatic merge functionality described in AutomergeIf both event logs have defined a sorting column, the resulting event log respects the merged sorting column for ordering events. The resulting event log also has a sorting column defined. If only one of the two event logs has a sorting column defined, the sorting column is ignored.
Timestamps of day-based activities from the timestamp input columns are never modified during the merge. This means that they stay the same even if the sorting rules for day based activities as described in activity table sorting would apply to the resulting event log.
Case ID Generation
In certain cases, it might happen that no case id for an activity from the merged eventlog is present in the target activity table. Due to the fact that join definitions between an activity table and a case table can generally be defined over multiple columns, we must generate new case ids. This is achieved by concatenating the columns of the target case table defining the join to the target activity table. If the generated case ids are not unique, a row number suffix will be additionally added.
Examples
[1] This example scenario contains two activity tables ACTIVITIES_BSEG and ACTIVITIES_BKPF joined to their corresponding case tables BSEG and BKPF. The relationship between BSEG and BKPF is n:1. In the example query, the activity column from table ACTIVITIES_BSEG is the first input parameter. Therefore, the activities from table ACTIVITIES_BKPF are merged into the corresponding cases of BSEG. The resulting (internal) table derived from the query is joined to BSEG. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
[2] This example scenario contains two activity tables ACTIVITIES_BSEG and ACTIVITIES_BKPF joined to their corresponding case tables BSEG and BKPF. The relationship between BSEG and BKPF is n:1. In the example query, the activity column from table ACTIVITIES_BKPF is the first input parameter. Therefore, the activities from table ACTIVITIES_BSEG are merged into the corresponding cases of BKPF. The resulting (internal) table derived from the query is joined to BKPF. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
[3] In this scenario, the two case tables 'CASE_TABLE_RIGHT' and 'CASE_TABLE_LEFT' are in a n:m relationship that is modeled via two 1:n relationships and the intermediate table 'LEFT_TO_RIGHT'. By using | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
[4] Like in the previous example, the two case tables 'CASE_TABLE_RIGHT' and 'CASE_TABLE_LEFT' are in a n:m relationship that is modeled via two 1:n relationships and the intermediate table 'LEFT_TO_RIGHT'. This time, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
[5] /* If both event logs have a sorting column defined, the merged sorting column is respected for the merge result. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
[6] This scenario shows that if there is no join partner in the source case table, the activities of the target table are still taken into account. Activities that are not connected to any case in the corresponding case table are ignored. | ||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||
|
[7] In this scenario one activity in the right eventlog does not have an entry in the corresponding case table. As a result, the activity does not show up in the resulting merged eventlog. | ||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||
|
[8] This scenario shows when there is no activity in the target table, but a join with the source table exists, then a case id is generated for the resulting merged eventlog. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
[9] This example scenario contains two activity tables ACTIVITIES_BSEG and ACTIVITIES_BKPF joined to their corresponding case tables BSEG and BKPF. The relationship between BSEG and BKPF is n:1. In the example query, the target table and source table are filtered. Hence, only rows which pass the filters are considered in the resulting merged eventlog. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
[10] This scenario shows the case id generation with multiple join columns. The join columns in the case table TARGET_CASE_TABLE are simply concatenated and use as case id. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
[11] This scenario show the case id generation with multiple join columns. The concatenation of the join columns from the TARGET_CASE_TABLE are not unique because string concatenation returns NULL again if it receives at least one NULL as input. Since we have multiple rows which are evaluated to NULL, we have duplicates and not produced unique case ids. Therefore, we append the ruw number as suffix to make them unique again. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
[12] Example to show that if a day based activity ("Enter in SAP") is on the same day as another activity after the merge, the timestamp of the day-based activity is not modified | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|