Integrating your data
The Celonis Platform allows you to view, analyze, and make improvements to your business process data. This data is captured by the tools and systems your business uses on a daily basis (which we refer to as your source systems). These source systems can be integrated with the Celonis Platform, helping you to extract the relevant data from them, transform that data to your needs, and load it into a data model for you to use throughout the platform.
Tip
Before getting started, consider exploring Industry reference architectures. Examples there show how data from different industries flows through the Celonis Platform architectural layers. If your specific industry isn’t listed, Architecture layers explained describes how each layer fits into your data landscape.
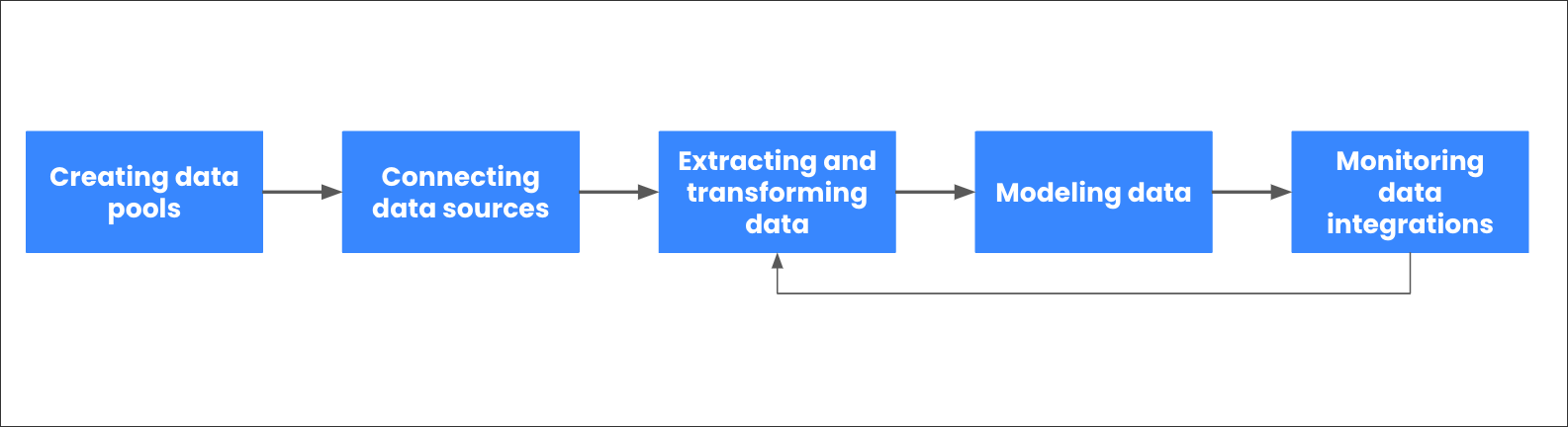
When configuring and managing your Celonis Platform data, the following stages are involved:
 |
Using the Celonis Free Plan?
If you're using Celonis Free Plan, you can view our Data Integration features only. This means that you are unable to create data pools or connect external data sources.
For more information, see: Celonis Free Plan.
Creating data pools
The first stage when integrating your source systems with the Celonis Platform is to create a data pool. A data pool is the main structural element of your data integration workflow, acting as a container for your data sources, data jobs, and monitoring.
For more information about creating and managing data pools, see: Creating and managing data pools.
Connecting data sources
After creating a data pool, you need to connect your data sources or source systems. You can do this in the Celonis Platform by creating and configuring data connections, with a number of input options available to you. The method you choose here is often dictated by your source system(s) you're using.
For more information about connecting and configuring your data sources, see: Connecting data sources.
Extracting and transforming data
Once a connection with your data source is established, you need to create and execute data jobs. These are tasks that extract and transform the data you require from your source systems, ensuring that only the relevant data is integrated with the Celonis Platform. Data jobs, and their related tasks, can be either created manually or added to your data pool as part of a process connector.
For more information about creating data jobs and extracting and transforming your data, see: Extracting and transforming data.
Modeling data
In the Celonis Platform, your data is organized into Data Models. These Data Models enable you to define and map out the business process data that you’ve extracted and transformed from your source systems. By creating a model of this data, you make it both human readable and consumable by other product areas such as Studio and Apps.
For more information about creating Data Models, see: Modeling your data.
Monitoring data integrations
With both one-time and continuous data integrations, knowing which data was been extracted, transformed, and loaded into data models is important. With the Celonis Platform, you have a number of monitoring options, such as data job alerts and custom monitoring.
For more information about monitoring your data integrations, see: Monitoring your data integrations.