Replication Cockpit FAQ
General | ||
What is the Replication Cockpit? | The Replication Cockpit is a data pipeline orchestration tool that allows you to replicate data from source systems to the Celonis Platform in real time. It complements existing Data Jobs, and is tailored specifically for real-time connectivity requirements. In the current version the real time extraction and transformations are supported. The full extraction and transformations (alternatively called initializations) are in beta version. | |
Who should consider using the Replication Cockpit? | The Replication Cockpit is tailored for real-time connectivity use cases. If you use business applications and Action Engine, you should first achieve real-time connectivity. | |
Which systems do you support? | Currently only pipelines running on SAP ECC real time extractor. | |
Is this available for Full Cloud and Hybrid? | Replication Cockpit is available only for the Full Cloud customers. | |
Commercial | ||
Is this included in current licenses? | The feature will be available at no additional cost as a part of Data Integration. | |
For existing customers, will a migration be required? | The Replication Cockpit has a different orchestration logic than the data jobs. Extraction setup is pretty easy, still some effort is required to define the new extraction logic. Transformation scripts should be re-written to adapt to the Replication Cockpit requirements. While the business logic remains intact, the SQL statements should be rewritten to persist the transformed data, rather than drop/recreate the Data Model on each execution. | |
Technical | ||
What are the prerequisites to use the Replication Cockpit? |
| |
Can the Replication Cockpit be used alongside the Data Jobs? | Yes, absolutely. | |
Do you know how long the extractions will take with this tool? | This of course largely depends on the traffic size. To give some perspective, below are statistics from two pilots that have been conducted in the early days.
* Average extraction time of the table with the longest duration | |
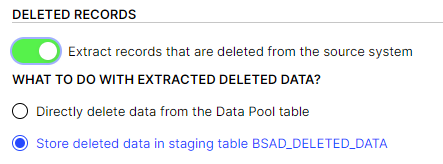
What are the different Deletion Options and which one should I choose? | You can select between three different deletion options on table level:
| |
How does the Replication Cockpit extract CDHDR & CDPOS ? | For CDHDR and CDPOS it is not required to have changelog tables in the Replication Cockpit. When you replicate data from these tables, we automatically apply a delta filter on the CHANGENR. This column can be used effectively to capture the delta because it is incremental. However, in a lot of SAP systems the CHANGENR is not 100% chronologically due to SAP processing transactions on different Application Servers. To address this, we always apply a negative offset of 5,000 to the CHANGENR filter. For example: max(CHANGENR) = 1,000,000 → Delta Filter CDHDR.CHANGENR. > 995,000 | |
What is an Initialization in the Replication Cockpit? | An Initialization is the term used in Replication Cockpit to describe Full Loads for Extractions and Transformations. The idea of a Full Extraction is that it is only executed once in the very beginning. Afterwards, the continuous delta loads make sure to capture all the ongoing changes on the data tables. An Initialization uses the column configuration and filters that are defined on table level (equivalent to the Replications). In addition you can define an Initialization Join (if required). This Join is only applied to Initializations. Its purpose is to be able to filter on certain date columns (start date) that are not present in the table itself but require the join on another table. | |