Task Mining data configuration and processing
About Task Mining data configuration and processing
You define how your Task Mining data will be processed, as well as any additional inputs, like labels and task definitions, in the Task Mining Data Configuration section of your Task Mining projects. You can:
Enable or disable out-of-the-box data transformations.
Set the schedule.
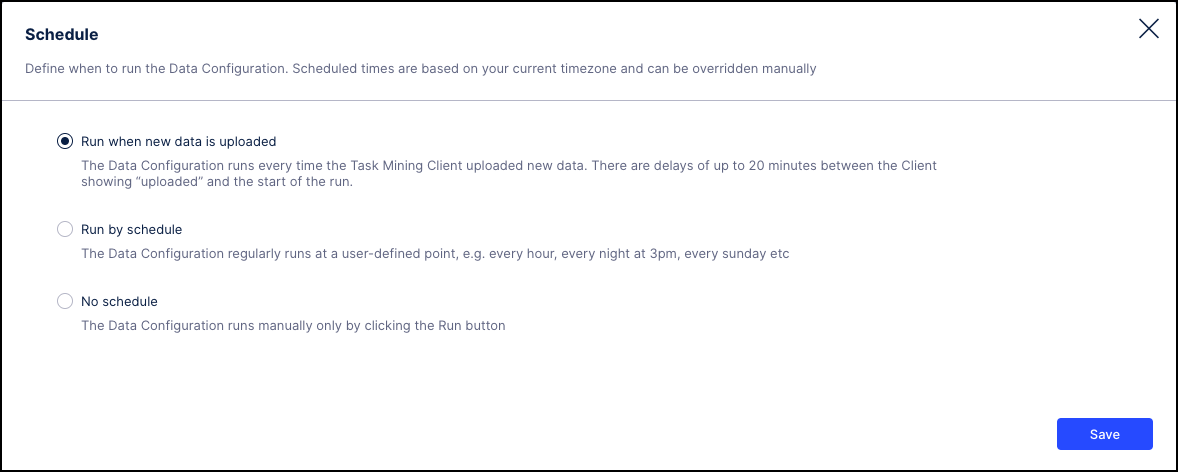
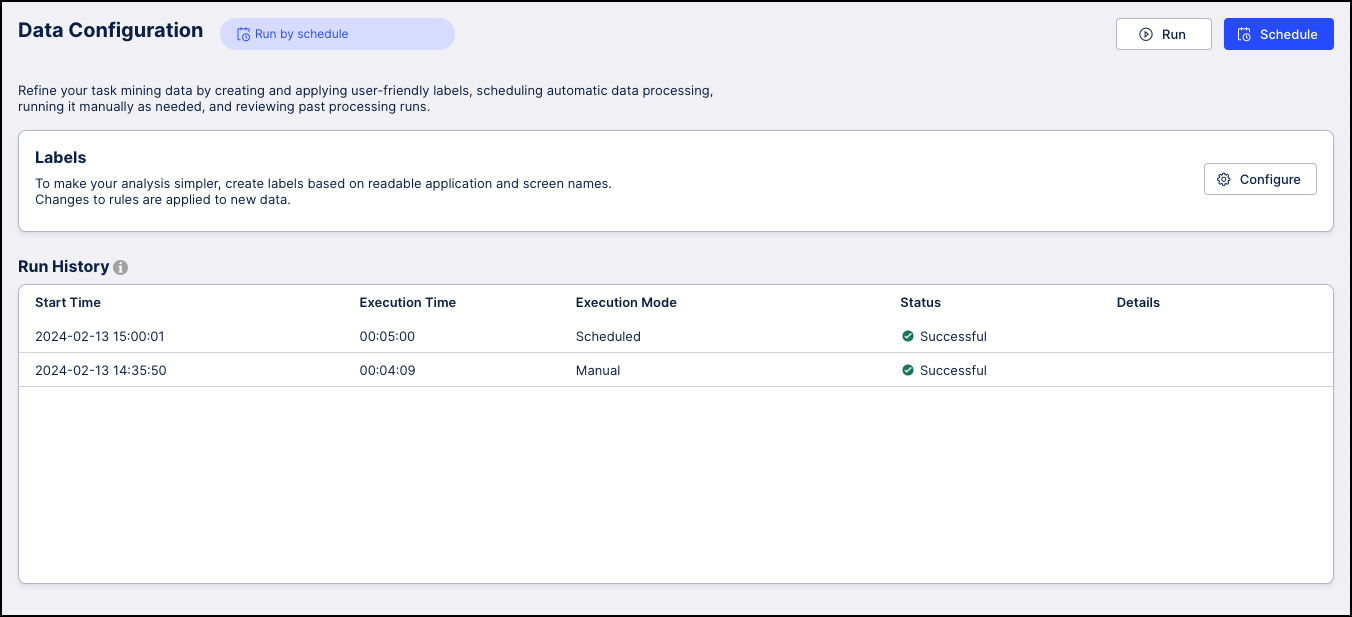
Monitor status and investigate potential issues.
How Task Mining processing works
In Task Mining, your captured data is processed automatically ‘out of the box’, allowing you to quickly and easily get insights into your processes and data. Depending on your business goals and use case, you’ll be guided to define Labels, Business Events and Tasks.
Task Mining processing flow
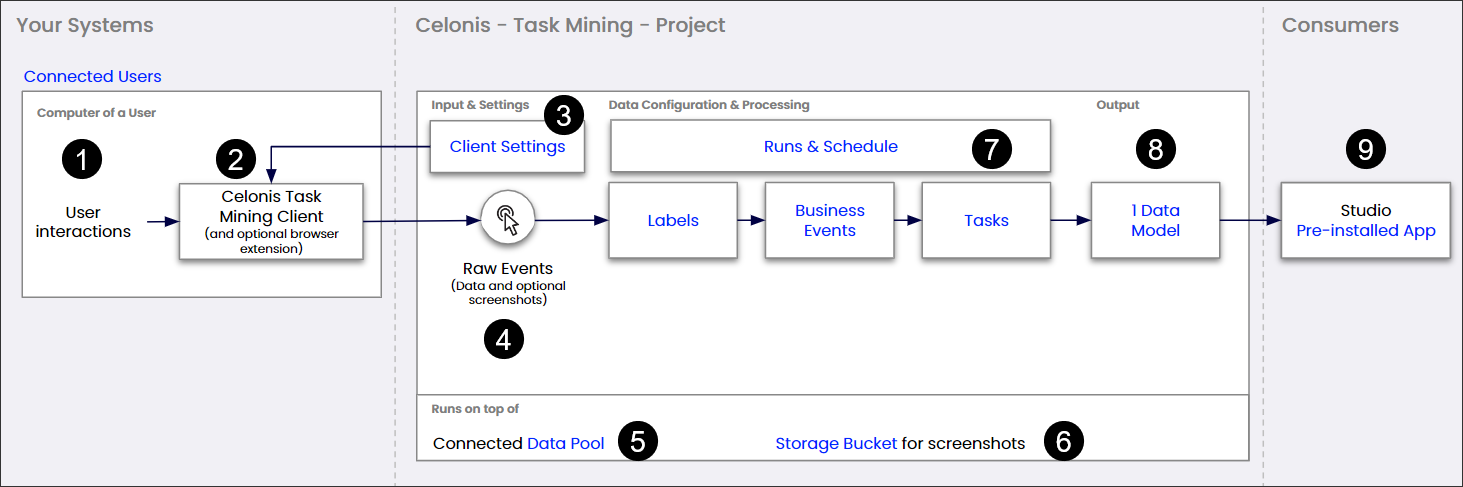
Part | Description | Further information |
|---|---|---|
 | Captured on user's computer using the Celonis Task Mining Client and an optional browser extension. | See Users & Invite for information about viewing connected users. |
 | Agent runs on user's computer and captures user interactions, generating raw event data (and optional screenshots). | |
 | Helps define data collection settings including which raw events and attributes are collected and how data is pseudonymized. | |
 | Data collected by the client, sent to the Celonis team and stored in a database. Includes user interaction events, such as clicks, keyboard shortcuts, and optional screenshots if configured. | |
 | Raw events and processed data are stored in a connected data pool which was automatically created when the project was set up. | |
 | Automatically created during project set up and optionally used to store captured screenshots. | |
 | You can configure and monitor the out-of-the-box data processing to manually execute a run or change when processing is triggered automatically. When a run is created, it applies the data configuration and processing settings below. | See Task Mining key structuring concepts for information about customizing labels, business events and tasks definitions to enrich your analysis. |
 | Processed data is structured into a data model that is automatically created during projet set up, represents the task mining insights and is automatically refreshed after a processing run. | |
 | Final data model and integrations are made available to end users via a pre-installed app in Celonis Studio, allowing users to visualize and analyze task mining insights. |
Task Mining processing limitations
Task Mining processing is limited by the number of:
Rows the data model can load into one table (typically two billion).
Concurrent users sending data per realm (up to 30,000 users for larger realms).
We take these limitations into account when testing Task Mining projects. For example, we might test a project for a maximum of 2,500 concurrent users per project with an average of six months of historical data.
If two billion events are analyzable, we might also extend historical data analysis to, for example, 24 months for 690 users assuming 5000 events per day and 20 working days per month. For more information, see Workforce productivity.
Task Mining key structuring concepts
Concept | Description | Example | Further information |
|---|---|---|---|
Raw Events | Unprocessed data points captured directly from user interactions or system activities These are granular, foundational records that provide the most direct information about what occurred. | A click on a login button Copy/Paste Window screen/session locked. | |
Labels | Attributes assigned to raw events to:
| Adding a label to an application or screen or labeling an event like screen ‘Login’. | |
Business Events | User-defined events that identify single user events and add business relevance to raw data, often linking to one or multiple related objects the event relates to. | Submit opportunity with an ID 413, where the raw event of clicking Submit on an opportunity is elevated to a significant business activity. | |
Tasks | Sequences of raw events that form a coherent unit of work and typically represent a user completing a set of actions towards a specific goal. A task typically represents an instance of work that takes a couple of seconds to a couple of minutes to perform. | Creating an invoice, including steps like entering customer details, adding item lines, and submitting the invoice. |
Data processing types
Note
You access these processing types from the Run button on the Task Mining UI.
Data processing type | Description |
|---|---|
Processes new incoming data only. Ideal for keeping your dataset updated with the latest information while keeping the data processing duration low so your data is updated as fast as possible. | |
Reprocesses all existing data to apply new or updated rules, labels, business events, or tasks. Consistently applying changes across the entire data set ensures your analysis is consistent. |
Processing new data (delta)
Client sends new data into the user_interaction_event_log table.
New data from user_interaction_event_log is processed:
Applies predefined ‘out of the box’ and user-defined labels to raw events; the enriched event is available in table TM_Labled_Data
Applies tasks, where the tables Tasks, Task_instances, and Tasks_Join contain the discovered tasks, with:
Tasks containing the list of task names defined by the user.
Task_instances linked to Tasks an containing zero or more found task instances.
Tasks_Join being a n:n join table between a task instance and tm_labeled_data events.
Note
Data is processed in batches of up to 10 million rows for efficiency.
Data model automatically reloads to reflect the newly-processed data.
Re-processing existing data (full)
Initiation: User triggers reprocessing through the UI.
Preparation:
Creates temporary tables in the background which don’t contribute to APC consumption; these are basically a copy of existing tables.
Copies all existing data from user_interaction_event_log and user_interaction_event_log_history into the newly-created temporary reprocessing tables.
Processing: Performs steps 2 and 3 of processing new data (delta) on batches of up to 10 million rows and repeats until all raw event rows have been processed.
Finalization: If successful: Temporary reprocessing tables are renamed to replace the original tables. The original tables are then replaced by the temporay tables which now contain the re-processed results. A reload of the data model is triggered to ensure the latest data is available for analysis. The new data is kept in the user_interaction_event_log table until the next scheduled processing.
Failure path: If reprocessing fails, all temporary tables created are dropped to clean up. The system sets the reprocessing job execution status to Failed and this is displayed in the Run & Schedule UI.