SAP ECC and S/4HANA data extraction overview
Celonis has developed a dedicated on-prem SAP extraction client to ensure a continuous data pipeline between the Celonis Platform and the source SAP system. This allows for the relevant tables to be continuously monitored for changes, and once a record is updated, the record ID is logged in a dedicated table. The next time an extraction is run, only the records that have been updated and logged will be extracted. The extractor then joins the tables and receives only the updated records. Since the join will be done on primary records, the delta filter is then performed.
The following components are involved in the extraction of data from SAP ECC and SAP S/4HANA:
Celonis Platform: This is where the extraction tasks are defined, allowing you to identify which tables are extracted, what filters should be applied, and what schedule the extractions run to.
SAP extraction client: This acts as middleware between Celonis Platform and the SAP system. Its role is to poll and fetch the job requests from Celonis Platform, and then submit the execution information to the Celonis RFC Module in SAP. Once the data is retrieved from SAP, the extractor fetches it from SAP and sends it back to Celonis Platform. This extractor should be installed on-premise.
Celonis RFC module: This is responsible for extracting data from the SAP database. It gets the job metadata from the extractor, i.e. which table, which columns, filters, etc, and then generates a background job in SAP. The job extracts the data and writes it in csv files in a directory that is monitored by the extractor. This package is imported into SAP and contains 12 functions.
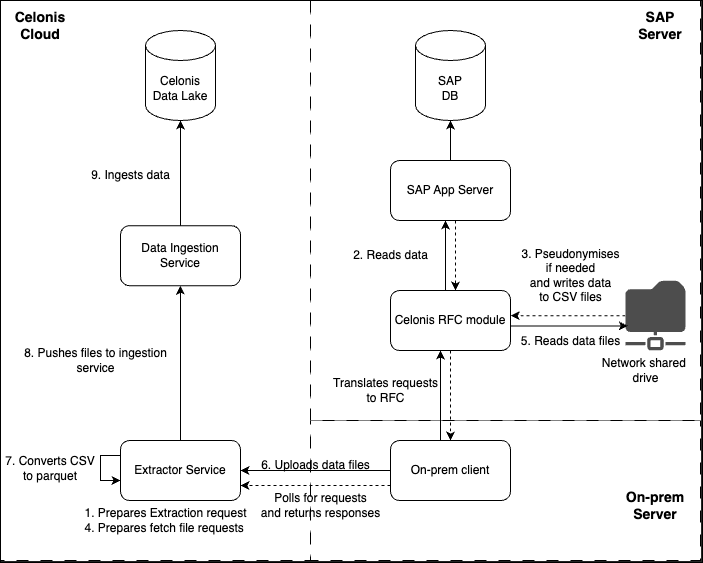
This is the workflow when data is extracted from SAP and sent to the Celonis Platform.
The extraction request is sent by the Celonis Platform.
The extraction request is published to a message queue, which is polled in real-time by the OPC. The indirect connection option has been implemented because of security reasons, to avoid inbound network calls. OPC passes the request to the RFC module which reads the data from the database according to the column and filter definitions.
RFC module writes the data to CSV files on the network shared drive in chunks (by default 50k rows in each file). The data can be optionally pseudonymized before being written to files.
The cloud extractor polls the network shared drive and sends fetch requests to the RFC module.
RFC module receives the fetch request and reads the data from the network shared drive.
OPC uploads the fetched files to the Celonis Platform.
The cloud extractor converts CSV files to parquet.
Extractor pushes the parquet files to Celonis.
The data is ingested in the Celonis platform and ready to be modelled.
And a diagram showing this process:
 |
The full end-to-end process is as follows:
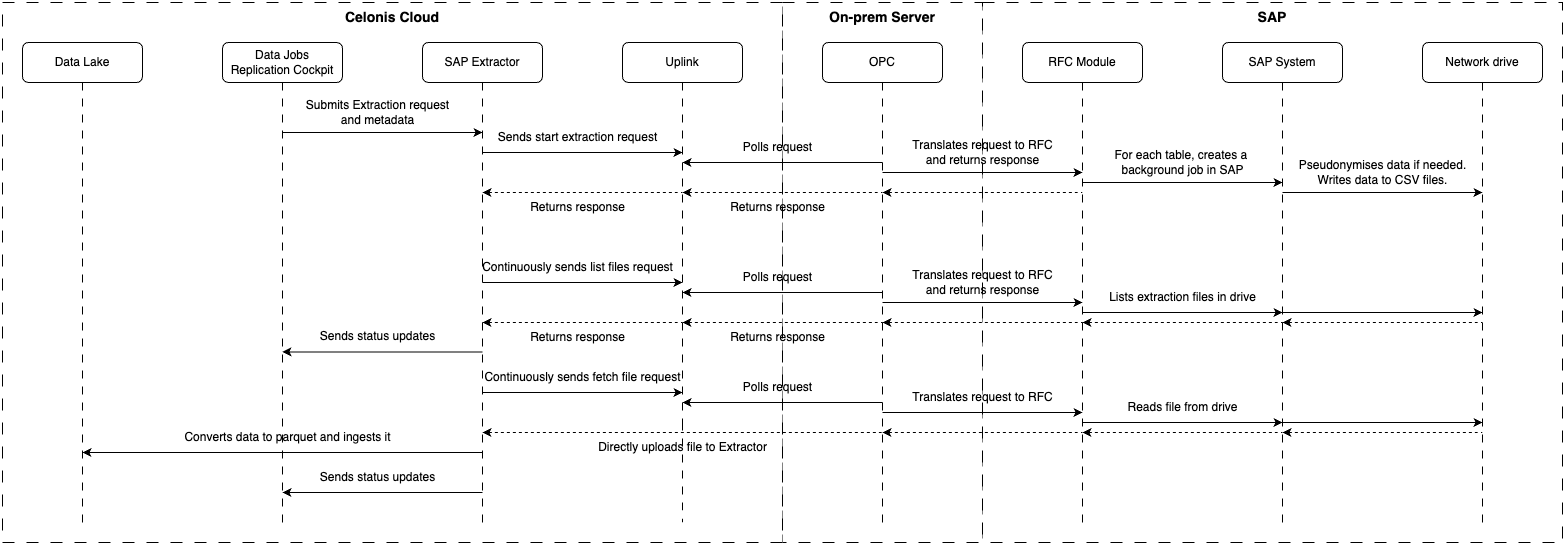 |
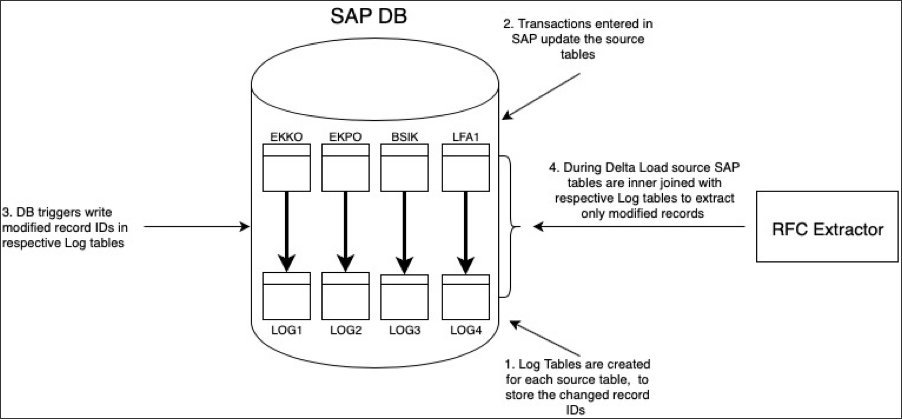
You can configure real time extractions from your SAP ECC and SAP S/4HANA systems. In case the real-time extraction mode is enabled, the extractor service calls the RFC function /CELONIS/EX_CL_NEW. For each table, it checks whether real-time extractions have been enabled or not. If so, modifies the extraction filter to ensure that only the changed rows are extracted, and then delegate the task to the /CELONIS/EXTRACTION program which follows the standard extraction flow, by writing the data to csv files and sending it to the extractor service and then to Celonis Platform.
Once the extraction is complete the RFC function /CELONIS/EX_CL_SET_EXTRACTED is invoked to flag the extracted records so that subsequent extractions only receive new changes. If the extraction failed, then the function is not invoked, records are not marked as extracted, and subsequent extractions will receive the same (and all new) changes until successful.
The diagram below explains how the real-time extractor operates:
 |