Enabling partitioned extractions of large tables
When you're looking at extracting large tables of data from your source system, you should consider using partitioned extractions. This allows you to chunk your data jobs into smaller batches which can then be extracted either in parallel or sequentially. These batches are then merged into a single table in the Celonis Platform and function in the same way as tables extracted in full.
By partitioning your data jobs, you're able to both reduce the extraction time and limit the chances of failure (often caused by high data volumes). The number of concurrently running extractions will be limited by the limit of parallel executions in your Data Connection settings. So even if you have 32 partitions, only the maximum allowed number will be run in parallel. The rest will be queued. This can potentially limit the performance gains.
Partitioning of extractions is supported only when the extraction mode is set to "Full Load".
The following source systems support partitioned extractions of large tables:
Salesforce
SAP
ServiceNow
JDBC (databases)
The partitioning is set up at the table level and in the data job extraction task:
Open the Table Configuration for the table you want to partition and toggle Enable Partitioned Extraction:
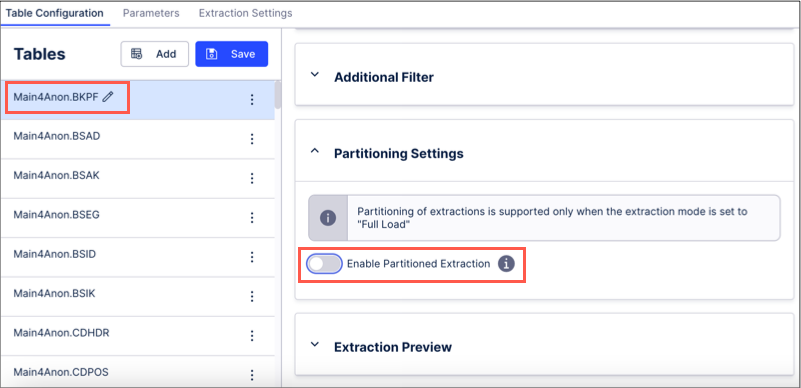
Click Configure.
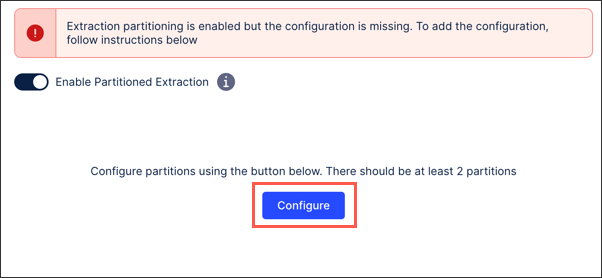
Follow the guided wizard, with further help for each step of the wizard provided below.
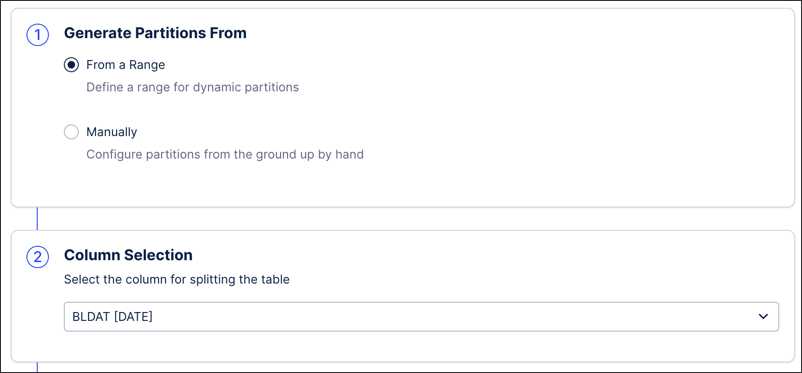
The first step is to define whether the partitions are dynamically generated from a user-specified range, manually, or from an existing time filter.
From a range:The partitions are generated dynamically before each extraction run. For example, when the lower range is bound to a parameter and the upper one is NOW(), the partition ranges will change automatically depending on when the extraction is run.
When configuring the partition from a range, you need to define:
The key column on which to partition, i.e. CreationDate. See: Step 2: Key column selection.
The lower and upper bounds of the range, i.e. 01.01.2020 - NOW(). See: Step 3: Range configuration.
Number of partitions - Automatically Calculated or Fixed. See: Step 4: Number of partitions.
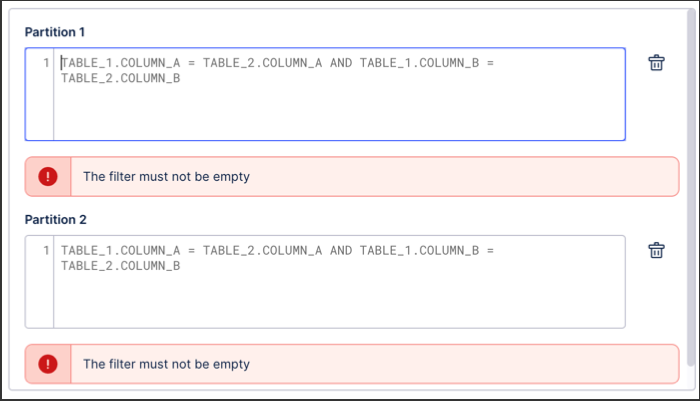
Manually: When the Manual option is selected, you must define each partition yourself by defining the filters.
Existing Time Filter: When the table you're partitioning has a time filter, the partition range and the column are automatically selected.
As a result, you see the additional option:

For the partitions to be generated dynamically from a range, you need to select the key column. This column should be of Date or Numeric type, so that equal partition ranges can be generated automatically.
The more equal the data is distributed across partitions, the more effective the extractions will be. The “creation date” columns are typically the best candidates for this.
 |
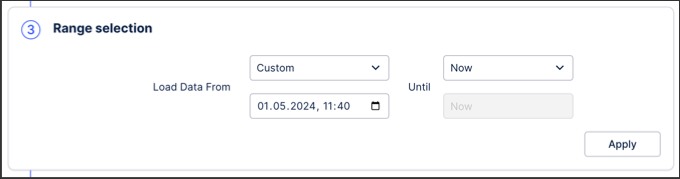
After the key column, you need to define the lower and upper bounds of the range. The bounds can be based on:
Data job parameters, i.e. StartDate.
Dynamic parameter NOW().
Hardcoded.
If you want to run a rolling extraction, i.e. extract 1 year of data on a monthly basis, you will need to apply an offset from NOW(). The offset is not directly supported, but as a workaround you can write a transformation that calculates the offset date in vertica every day, i.e. NOW()-365, and then assign it to a parameter. Afterwards, you can use this parameter as the lower bound in your range.
 |
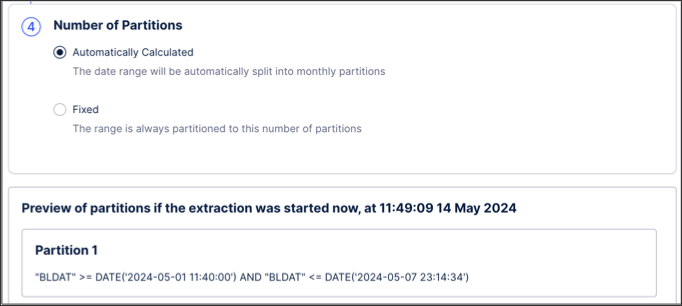
To partition the date range, the formula needs the number of chunks. It can be either calculated automatically on runtime or be fixed.
If automatic: the range will be split into quarters. This option is recommended when you have a dynamic range which changes on each runtime.
 |
When extracting joined tables, you need to select which table to generate your partitions on (either the main table or the join partner).
For example: CDPOS has no date field to run the partitions against it, and therefore we recommend joining on CDHDR to be able to filter on the UDATE.
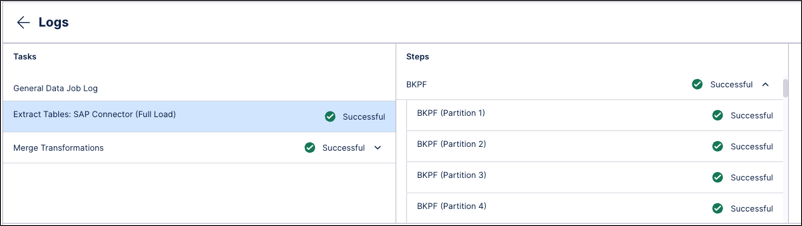
When the partitioning is active, the table is extracted in several chunks and then merged via a transformation. This is captured in the Data Job logs.
For each partition, a separate extraction task is created as if it is a table of its own. The table is pushed to the Celonis Platform as an independent table.
For example, if you are extracting table BKPF from SAP ECC with 4 partitions, then the extraction will create four jobs and upon completion four tables in the cloud - BKPF_0, BKPF_1, BKPF_2 and BKPF3.
Once the extraction has finished, a merge transformation is executed to combine these tables into a single one, in this case BKPF. The partitioned tables are then cleaned after five days.
 |