Machine learning workbench best practices
When using the machine learning workbench (MLWB) capabilities, we recommend the following:
When setting up your machine learning workbench environment, you should first distinguish between development and production environments:
Development Environment: Used for prototyping and testing.
Production Environment: Used when deploying production-ready scripts and applications.
Once your environments are decided, set up your resource pools for this environment. For more information, see Managing resources and consumption.
Workbenches
Once your workspaces are configured, you can now set up your workbenches.
In the following example, the team decided to assign each developer a dedicated development workspace.
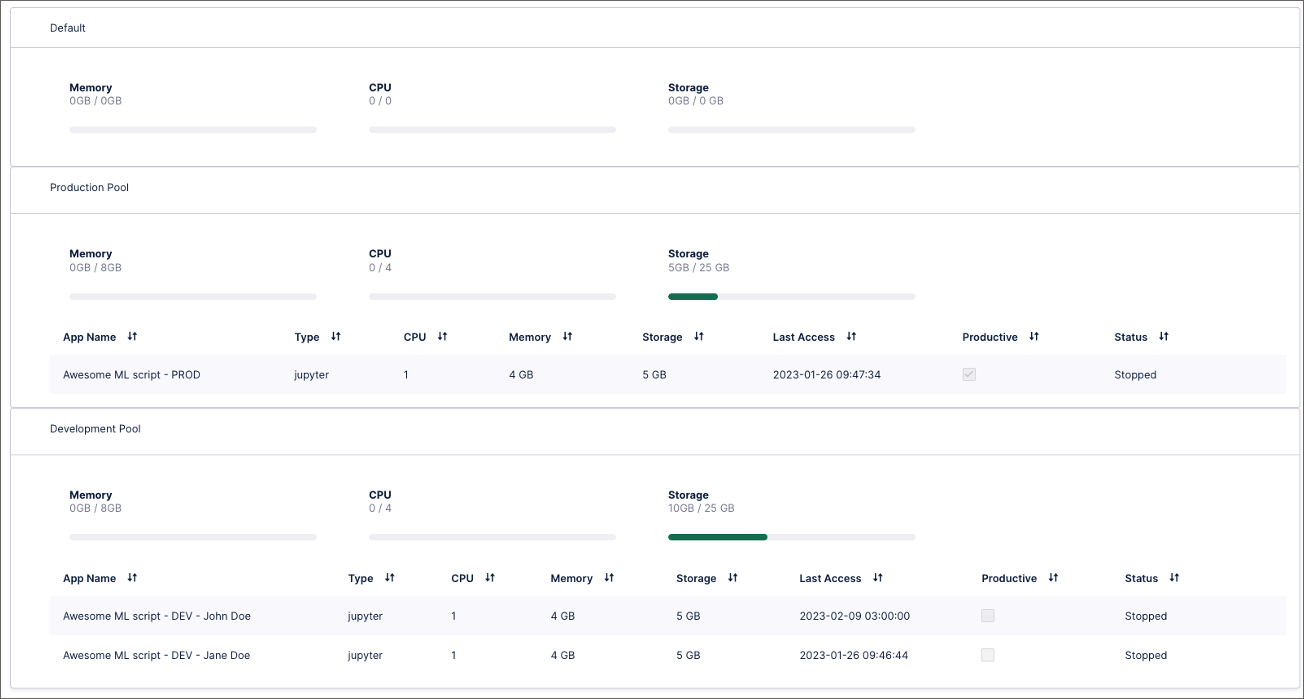
Because their workbenches have all been initialized with the same repositories, each developer implements their part of the script in their corresponding feature branch. This approach allows developers to work in parallel, rather than within the same environment.
The final and stable version of the script is then based on the default stable branch, rather than manually updated. This script then runs in a dedicated workbench in the production workspace, with that workbench set to productive. This ensures that the workbench is never automatically shut down.
Development Environments
When setting up development environments, we recommend following these principles:
Ensure optimal resource allocation by distributing resources as necessary among the notebooks.
Maintain efficient resource utilization by promptly shutting down notebooks that are no longer required.
Production Environments
When setting up production environments, we recommend following these principles:
Limit the number of notebooks within the machine learning workbench by calculating the required resources and allocating a finite number of notebooks accordingly.
Clearly identify productive notebooks by marking them as such in the configuration tab.
Implement a structured resource allocation strategy by distributing resources in a fixed manner.
Notebooks
When creating a notebook, we recommend following these principles:
Ensure consistency by checking out the main branch in all production notebooks.
Implement an organized development process by performing development work in designated feature branches.
Maintain accountability by having only one person work on a single feature branch in a single notebook at a time.
Keep development and production environments separate by only using development data pools in development notebooks.
Preserve the integrity of production data by only using production data pools in production notebooks.
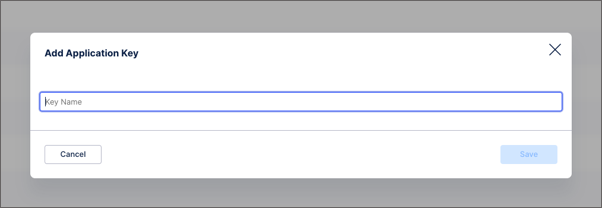
When connecting your machine learning workbench to a data model, we recommend that you use an application key. Application keys are user-independent API keys, allowing you to assign granular permissions to your applications rather than to individual users.
Application keys are created by account administrators in Admin & Settings. For more information, see Application keys.
 |
You can still create a personal API key, however you should only use these for a private machine learning workbench and not to grant permissions to other users.
When using IP restrictions in your Celonis Platform, the outbound IP of the machine learning workbench must be excepted.
Note
The IP addresses for machine learning workbench VM/apps are different than the IP address for the main Celonis Platform. The IP address for each MLWB VM/apps is unique.
To find your outbound IP, run the following command on the terminal of your machine learning workbench:
curl ipinfo.io/ipThen for more guidance on allow listing Celonis IP addresses, see Allowlisting Celonis domain names, IP addresses, and third-party domains.
There are a number of API endpoints available, allowing you to trigger executions, manage resources, and more. You can check our External Machine Learning APIs inside our Swagger UI page. To access the Swagger UI, use the following URL:
https://[teamname].[realm].celonis.cloud/machine-learning/swagger-ui/index.html#/
For more information, see the Celonis Developer Center.
Machine learning workbench can be upgraded to the latest version (e.g. to get new features for Jupyter Lab) using the context menu in the MLWB overview page.
Note
Upgrading a workbench will have no impact on the files on /home/jovyan. This includes user generated files and log files. Also, no changes to the versions of the already installed Python libraries are made.
In case of a bigger change (e.g. upgrading the version of python) an additional message is displayed asking for the confirmation of the user.
Initial Storage
Default machine learning workbench apps boot with 5GB Storage total, 1.2GB already used. Below is an example of the initial Storage bar on a new machine learning workbench App.

This is 5GB per machine learning workbench app, not 5GB shared across all machine learning workbench apps of a team.
The 1.2GB used from the start are for the machine learning workbench setup (same as a new 64GB iPhone which only has 58GB available because of the iOS storage).
Storage tips - Current Storage
To view the largest files/folders, you can use the terminal to run any of the following:
For Overview top 10 top-level folders in nice format:
du -hsx * | sort -rh | head -1
For Detailed top 10 any folders in raw format:
du -a /home/jovyan | sort -n -r | head -n 10
Storage Tips - Cleaning/Deleting Storage
Since deleting folders isn't possible with the typical right-click, use the terminal to run:
rm -rf foldername
Note
Make sure you reference the folder with an absolute path or correct relative path.