Examples of Web Page Data Extraction
Simple Example
In this example, we will show how to define web page data extractions. For this purpose, we create two custom rules to extract data from different web pages.
Rule 1: Web page title
Key |
|
URL |
|
Path |
|
The first rule extracts the title of the web page which is usually stored in the title element of the document head. The given URL pattern \w* matches any string, so the extraction will be done for any web page.
Rule 2: Top-level headers Task Mining help page
Key |
|
URL |
|
Path |
|
Important
The old URL of celonis.cloud/help/display/CIBC/Task\+Mining no longer exists and redirects to the main page. Please use the new URL above.
The second rule extracts all headers on top-level from the web page. However, this data is restricted to the main task mining help page. Please note that the plus symbol (+) in the URL is a special character in regular expressions so it must be escaped with a backslash (\). Additionally, team domain and realm are omitted from the URL to avoid a restriction to a specific team or realm.
Results
For every user interaction on the Task Mining help page (Task Mining (legacy)), the following data is extracted and stored in the WepPageExtractions column:
[
{
"key":"webpagetitle",
"data":[
"Task Mining - Celonis Intelligent Business Cloud - Help Space - Celonis Cloud Help"
]
},
{
"key":"headers",
"data":[
"Celonis Cloud Help",
"\n Task Mining\n ",
"Overview",
"What is Task Mining",
"How it works",
"What Information is sent?",
"User Interface",
"Flag notifications"
]
}
]For user interactions on other web pages, only the title will be extracted, as they do not match the URL pattern of the second rule. For example, the user interactions on https://www.celonis.com/ will provide the following result:
Result for user interactions on https://www.celonis.com/
[
{
"key":"webpagetitle",
"data":[
"Celonis: The World's #1 Process Mining Software. Become a Superfluid Enterprise."
]
}
]Real World Example: Extract number of search results given in Google

1. Define Name of Extraction
You can choose any name you want that will then appear in the Web Page Extractions and can be used to retrieve the extracted value.
2. Define URL
The URL should be as specific as possible and still include all cases you want to capture. For our example it would begoogle.com/searchas:
Just using google.com is too generic (might also include google sheets etc.)
The full URL (https://www.google.com/search?source=hp&ei=2M-...) is too specific and would not capture all searches
3. Define XPath
XPath Documentation:https://www.w3schools.com/xml/xpath_syntax.asp
In order to define the XPath, we navigate to the page in Chrome and right-click on the element we want to extract, and choose to inspect.
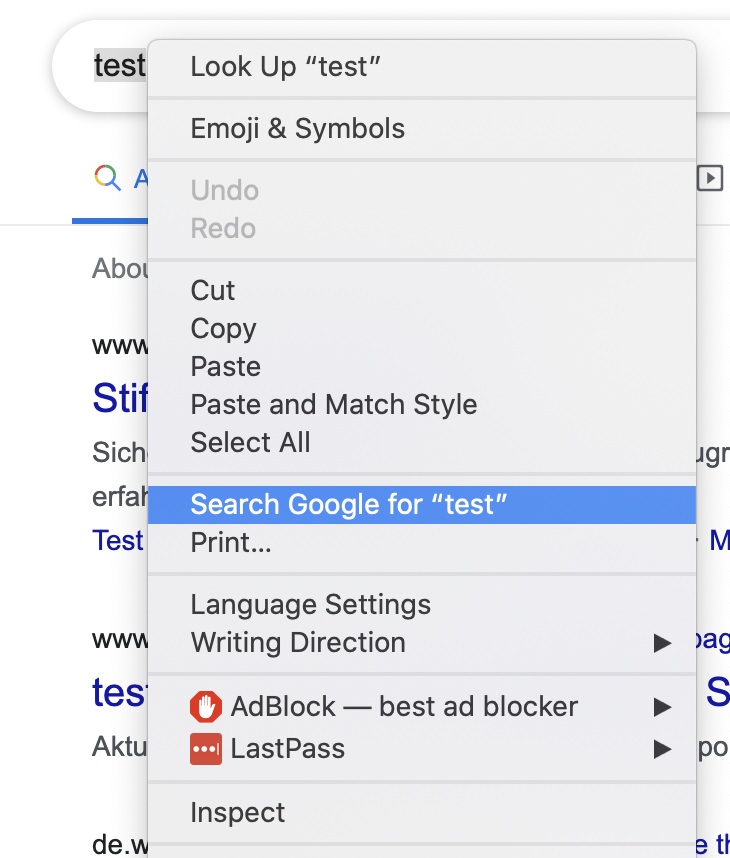
The developer console opens and we see the selected element (marked in blue):
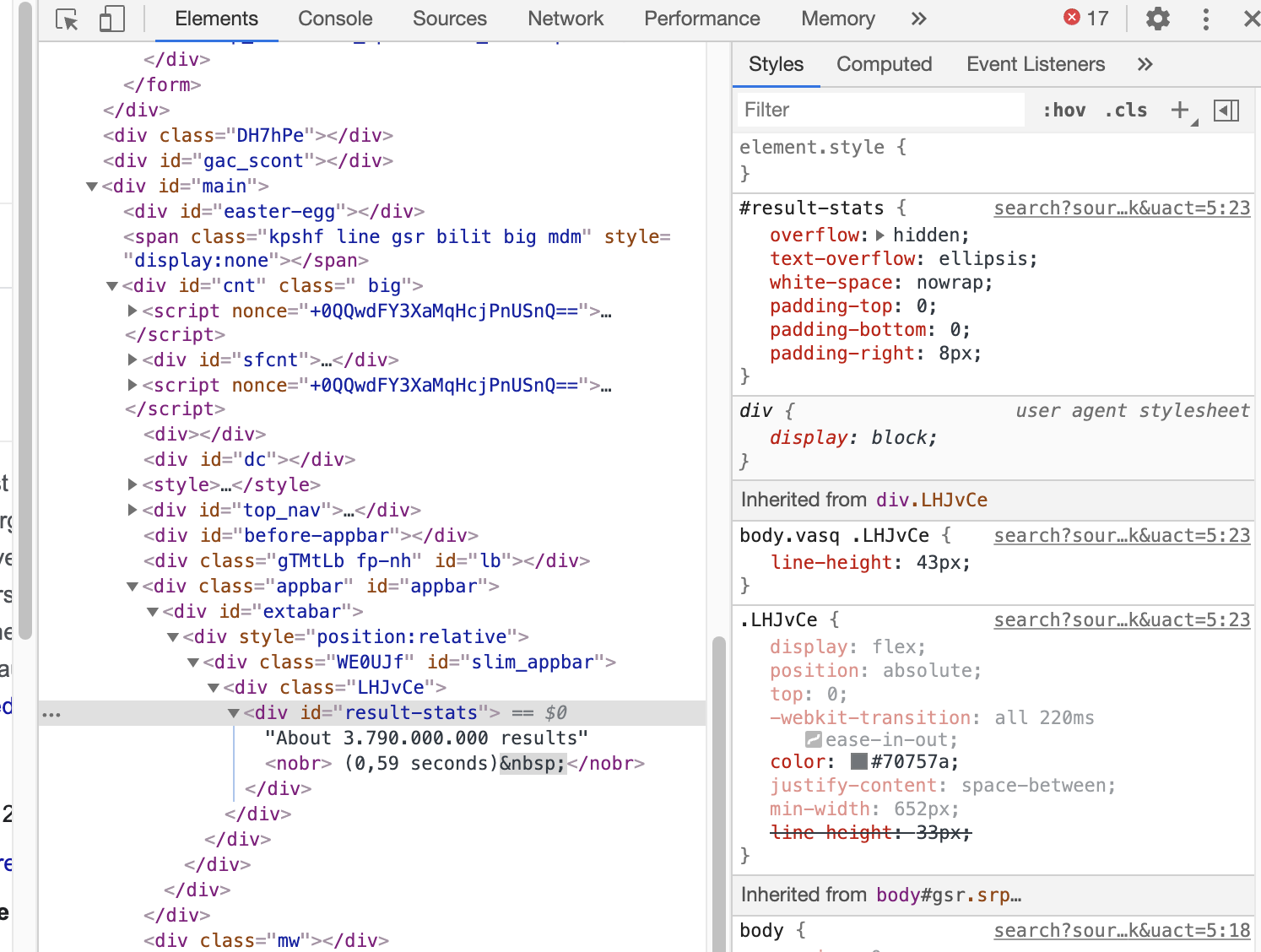
In our case we see that it is a <div> with an id set which is the best case for extracting as we can just design an XPath selecting for this specific id:
//div[@id='result-stats']/text()
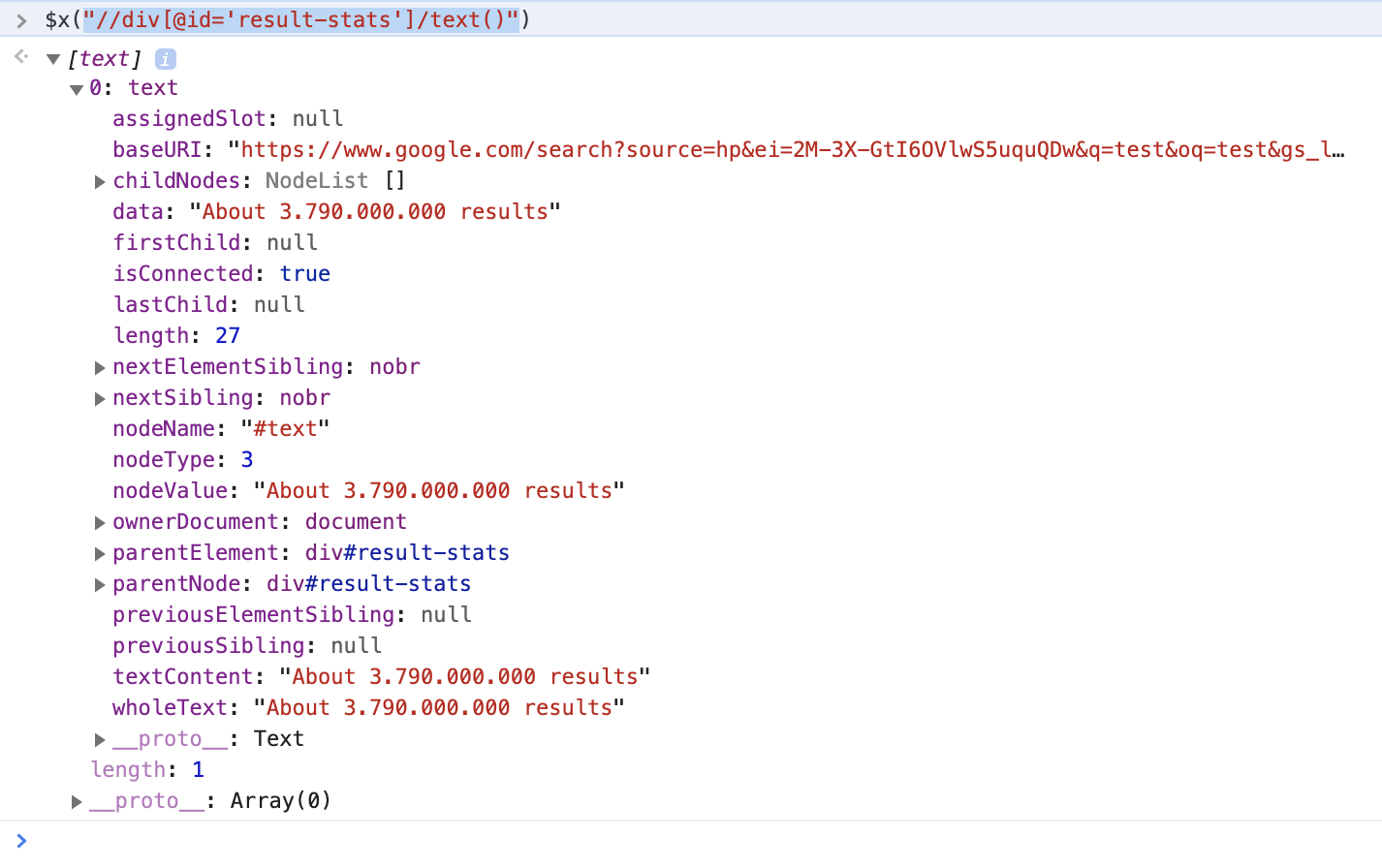
In order to test whether the XPath selects the wanted element navigate to theConsolein the developer console and test it by entering the following (add $("replace-this-with-your-xpath") around it) and hitting enter. For the example above:
$x("//div[@id='result-stats']/text()")When expanding the result you can see that one text value was selected which contains the wanted information:
Note
Often, the wanted element does not have an Id with which it can be selected. For those cases, it is important to use relative paths and not absolute paths as they often change.
If we pretend that our example did not have an id, we would then look at the parents in the DOM tree of the element:
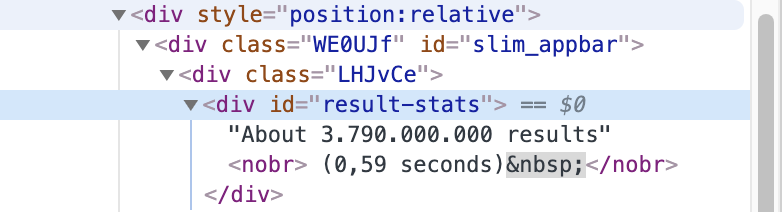 |
We can see that one of the ancestors has an id“slim_appbar”.Thus, we design an XPath relative to our element:
//div[@id='slim_appbar']/div/div/text()
Testing it again using $x(“//div[@id='slim_appbar']/div/div/text()”) shows that it again finds the wanted element:
One other way to extract an element would be to use an XPath searching for a specific text contained in an element. In our case we would look for “About” and “results”:
$x("//div[contains(text(), 'results') and contains(text(), 'About')]/text()")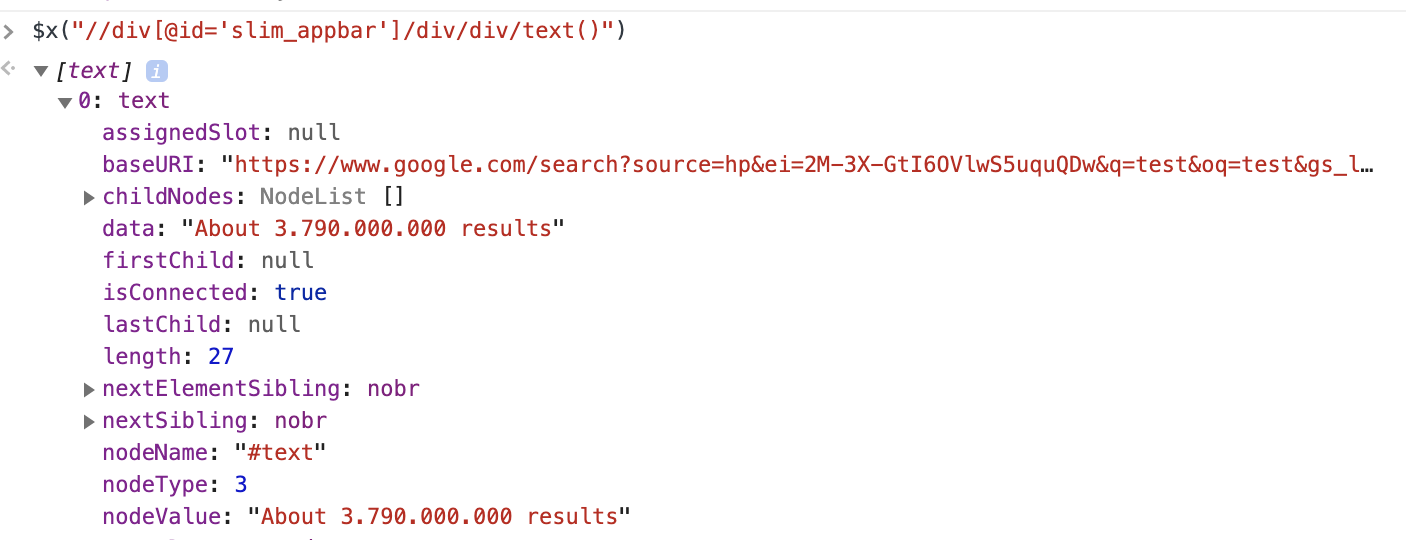 |
However, keep in mind that if any search result would contain both “About” and “results” it would also be selected by the WebPageExtraction.
In general, be as specific as possible with the XPath (e.g. using Ids) but keep in mind that websites can frequently change so it is important to use relative paths!
Also, many websites use generated Ids (e.g. “avwdfe-sa”). Avoid using these in the XPath as they frequently change!
4. Put everything together
Now you can put everything together and enter it in the configuration editor:
<WebPageDataExtraction>
<Key>NAME-OF-YOUR-EXTRACTION</Key>
<Path>XPATH</Path>
<Url>NAME-OF-THE-URL</Url>
</WebPageDataExtraction>E.g. for the specific example above:
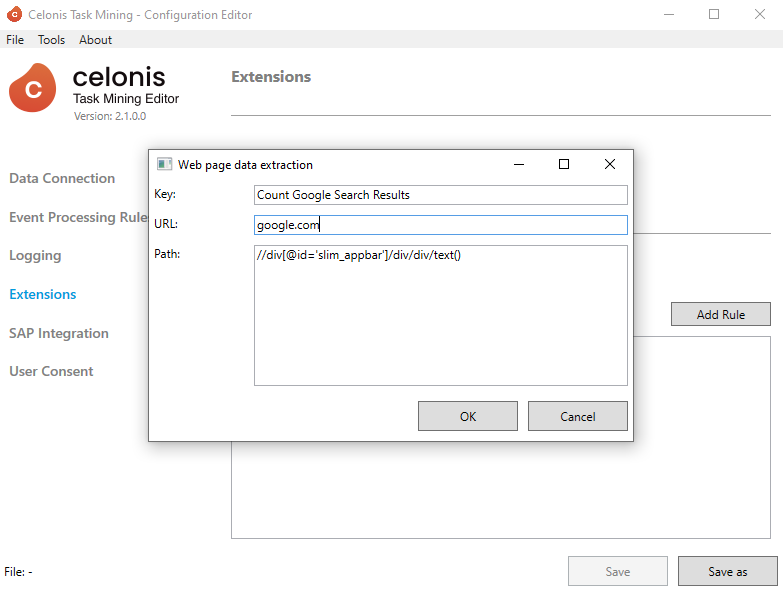
<WebPageDataExtraction>
<Key>Count Google Search Results</Key>
<Path>//div[@id='slim_appbar']/div/div/text()</Path>
<Url>google.com</Url>
</WebPageDataExtraction>And this is how it would look in the Config Editor UI:
 |
Real World Example 2: Extract support case id from salesforce
1. Investigate and define extraction rule
E.g. use the Chrome developer tools to come up with an extraction path
2. Update the "Client settings" to add the web page extractions, and save the new configuration in the Celonis Platform Task Mining settings
3. Restart the Task Mining Client to force fetching the latest config and avoid waiting up to 5 minutes
4. Restart the Browser so that the extension will use the latest configuration
5. Visit the web page and check that your data extractions are working as expected.