Creating a data connection between SAP and the Celonis Platform
The SAP connection offers several options to configure the extractions. These options are accessible using the data connection settings.
Before connecting, ensure you meet the following requirements:
Install the extraction client.
Install the RFC module.
Set up a technical user with relevant permissions in your SAP instance.
You can now create a data connection between SAP and the Celonis Platform from your data pool diagram:
Click Data Connections.
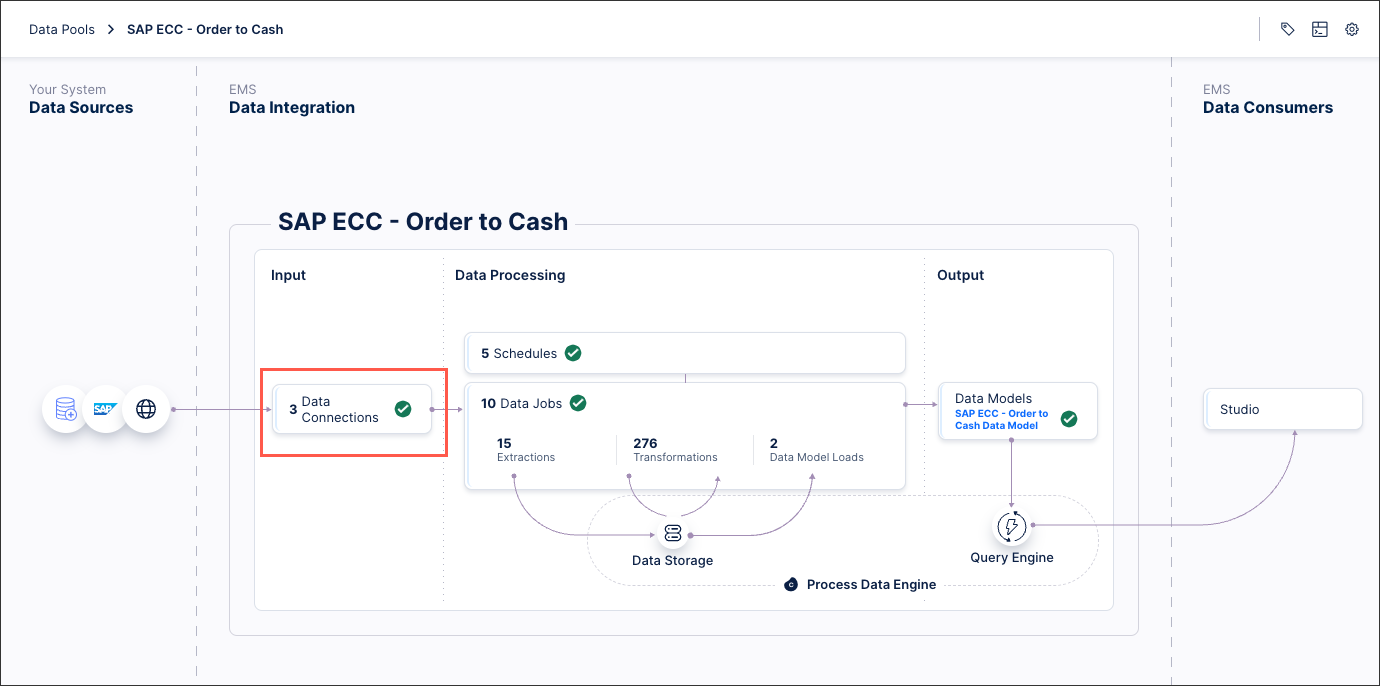
Click Add Data Connection and select Connect to Data Source.
Select the source type based on this table:
S/4HANA
SAP ECC
SAP ECC 5.0
SAP ECC 4.6C
Supported Version
All
minimum SAP ECC 6 EHP 4
only SAP ECC 5.0
only SAP ECC 4.6c / 4.7
Connection type
(when creating new Data Connection)
SAP
SAP
SAP
SAP 4.6C
Note
Available based on request.
Required RFC module
Celonis_RFC_Data_Extraction
Celonis_RFC_Data_Extraction
Celonis_RFC_Data_Extraction_ECC5
Celonis_RFC_Data Extraction_ECC4.6C
Unsupported features
-
"Buffer chunks in memory for validation"
Changelog Extractions
Joins within the Extraction
connection via middleware (SAP PI/PO and Message Server)
advanced settings
Configure the following connection details:
Name: The name assigned to this connection.
Host: Hostname of the system.
System number: A two-digit code, e.g. 00.
Client: A three-digit code, e.g. 100.
User: The user that was created in Step 1.
Compression type: Choose "Native Compression" if supported (recommended), otherwise GZIP, SAPCAR or uncompressed (not recommended).
Maximum parallel table extractions: Enter the number of tables that can be extracted in parallel.
Click Test Connection and correct any issues highlighted.
If you receive an error, check your connection details, then verify that your user is not locked and the SAP system is running. If a connection can be established, you will be redirected back to the connection overview and you will see a notification that the connection has been established.
Click Save.
Tip
Unless you're using an older version of SAP, 4.6C or earlier or you use PI/PO, we recommend installing the SAP Extractor as part of the on-prem client installation process. See On-premises clients (OPC).
In most of the cases extractor will connect to SAP system directly. However, sometimes there is a middleware which mediates all connections between external services and SAP.
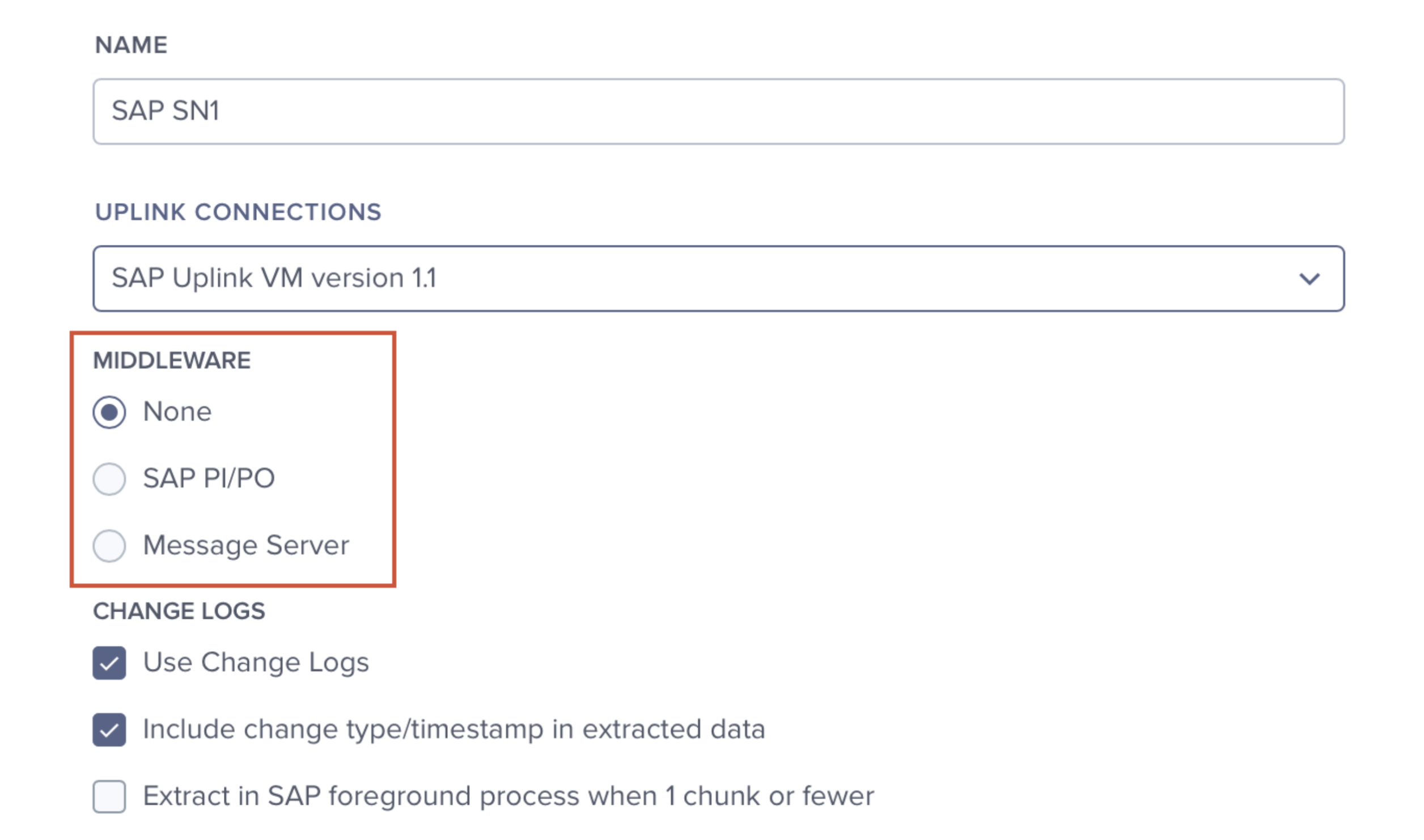 |
SAP PI/PO
The SAP PI/PO option enables the connection using PI/PO (more information). Once it is selected, the PI/PO Adapter dropdown becomes available with two options: RFC or SOAP. Depending on the selected adapter, the standard or generic SOAP extractor should be used.
Important
The middleware options for SAP PI/PO require specific extractors that are not generally available. To use either the RFC or SOAP option, you must request the appropriate extractor from the Celonis Service Desk.
RFC
Select this option when the PI/PO uses RFC Adapters to connect to SAP. The standard on-premise SAP Extractor can be used with this option.
Note
The on-premise SAP Extractor must be requested through the Celonis Service Desk.
The following fields should be defined:
Gateway Host: The host of the PI/PO system to which extractor should connect.
Gateway Port: The port port of the PI/PO system to which extractor should connect.
Program ID: The program ID of the Celonis program in PI/PO.
SOAP
Select this option when the PI/PO uses SOAP Adapters to connect to SAP. In this scenario, the Generic SOAP PI/PO Extractor, should be used rather than the standard SAP Extractor.
Note
The SOAP Extractor must be requested through the Celonis Service Desk.
The following fields become available:
Use TLS: Select this if you want to connect to the WSDL endpoints via HTTPS.
WSDL Files Directory: Enter the directory where the WSDL files have been coped (see the info above).
Note
When using the SOAP Extractor, you must generate the WSDL files, and should place them in the same directory as the Celonis Extractor.
Though it is possible to place them in other locations, for maintainability, we suggest to place them in the same directory as the extractor.
User: The PI/PO user for the authentication.
Password: The PI/PO user password.
Message Server
Enables connecting to an SAP server through Logon Groups (SAP Load Balancing). Using this approach the connection to a Message Server is established which is mapped to specific application servers. See Advanced configuration for more information.
Use Change Logs: Enables the Real-Time Extraction via Change Logs (more information).
Include change type/timestamp in extracted data: Extends each table with a column about the change type (insert/update) and the respective change date.
Extract in SAP foreground process when 1 chunk or fewer: Small amounts of records are extracted via "direct call" to bypass the background job queues. This speeds up the extraction times.
Chunk size: The number of entries that are contained in one chunk (default: 50,000).
It's possible to turn chunking off entirely by adding the following statement in the on-premise Extractor package:
chunked: falsein the fileapplication-local.yml.Number of rows to store in memory: Number of rows from the joined table to store in memory (default: 10,000). This number can be lowered in case of memory issues.
SAP Job Prefix: Defines the naming convention of SAP background jobs (default: "CEL_EX_") (more information).
Run on any SAP Server: If activated, the server on which the SAP background job should be run is not specified. SAP then decides the server to run it. By default the current application server is selected. This option includes SAP high availability systems.
Buffer chunks in memory for validation (reduce the Chunk size when enabled): This option should only be enabled when there are issues with corrupt files as it slows down the extraction process.
Number of retries in case validation fails (default: 100)
Retry interval (seconds) (default: 30)
Extract Change Log data of the specified client only: When you enable this setting, the real-time extractions will only extract the data for the client that is defined in the connection. When you disable it, data from all clients is extracted.
SAP systems are usually multi-client environments, where different clients are writing to the same database and tables. However, the real-time extension triggers are client independent, meaning that they capture changes by all clients and log them in the same Change Log table. This may create complications if two separate clients want to extract from the same system, and you can use this setting if you need to avoid that type of issue.
It's also possible to enable or disable this setting by adding the following statement in the on-premise Extractor package:
clientDependent: true(to enable) orclientDependent: false(to disable) in the fileapplication-local.yml.Disable auto deletion of old files in Z-CELONIS_TARGET: Disables the automated clean up of the "leftover" files from the Z_CELONIS_TARGET folder. This option should be selected if advised by your Celonis team.
Use non-chunked Change Log: When using the Change Logs for real time extraction, the data is read in a chunked manner by default to avoid deadlocks in the database. Select this option to override that setting and allow the data to be read without chunks. This option should be selected if advised by your Celonis team.
Use non-chunked Change Log cleanup: When cleaning up the data from the Change Logs, the data is cleaned up in chunks by default to avoid deadlocks in the database. Select this option to override that setting and allow the data cleanup to be done without chunks. This option should be selected if advised by your Celonis team.
Enable cold data extraction: Check this box to archive old data and free up working memory. The table is partitioned based on the age of the data, so the aged data is moved to the persistent memory and is not available unless it is explicitly invoked. Selecting this option makes the aged data available for extraction along with the current data. To extract old data, you must have RFC module 3.8.0 or later installed. For more information see, Extracting aged data.
Use SNC (SAP Secure Network Communications): Enables data encryption between the RFC module and the extractor via SNC.
Enable data extraction via staging table: This feature is supported by RFC v3.9.0 and above. Apart from this setting, no additional setup is required. The data will be stored in a database table during the extraction and is cleaned up once the extraction is complete.