Creating extraction tasks
As the name suggests, extraction tasks allow you to select the data tables to be extracted from your source system (and imported into the Celonis Platform). When configuring your extractions, you can apply time filters, add pseudonymization, and join tables to each other.
You can either create extraction tasks manually from your data jobs or edit existing extraction tasks (whether originally manually created or as part of a process connector).
Creating and managing extraction tasks
To create an extraction tasks from your data pool diagram:
Click Data Jobs and select an existing data connection scope.
In the extraction row, click + Add.

Add an extraction task name (an internal reference only) and click Save.
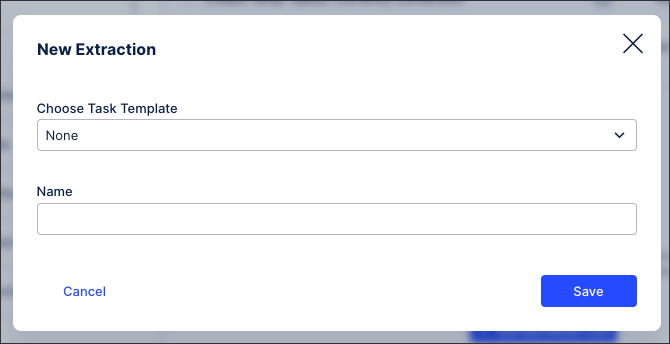
The task is created and displayed.
Edit your extraction task configuration as required. See: Extraction task configuration.
Extraction task configuration
When creating or edit an existing extraction task, you have the following configuration options available:
Table configuration
This is where you select and configure the data tables you want to extract. Depending on your data connection type, you have the following table configuration options:
Column subset: Specify which columns should be extracted by clicking Configure next to the column count.
Pseudonymized columns: As part of the advanced settings for data connections, you can pseudonymiz the data you extract using SHA-1, SHA-256 (with and without salt), and SHA-512 (with and without salt) algorithms. If you select to pseudonymize your data, values as displayed in the source system will be replaced with hashed values.
Pseudonymization happens during the data extraction. Celonis requests source system data, then pseudonymizes that data upon receipt, converts it into parquet format, and then ingests this into the Celonis Platform.
For more information, see: Extractor builder.
Primary key columns: You can explicitly specify which columns should be used as primary key columns during a delta load. This is only necessary if the source system does not provide this information on its own. Overriding the primary key columns does not change how data is stored in the database. It is only used for delta loads and not saved.
Removing duplicate records
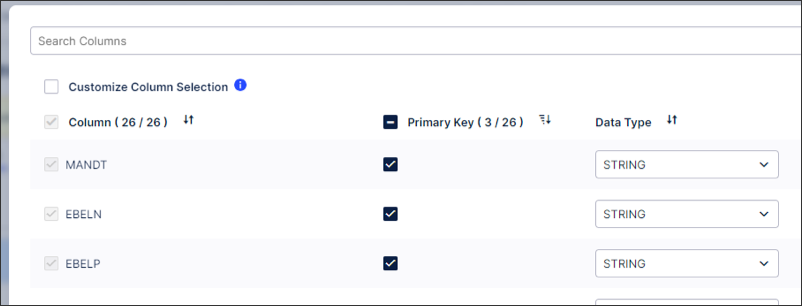
You can remove duplicate records when executing your JDBC extraction tasks by selecting the ordering column to be used:
 |
This feature uses the primary key configuration to determine what records are duplicated and then removes that duplicate based on the ordering column in descending order. As a result, we recommend using a timestamped column as your ordering column. When two or more duplicates are found, the oldest record will be removed.
In this example, we're using the columns MANDT, EBELN, and EBELP.
 |
Join configuration
You can add one or multiple join partners to the table. Each join partner can either be joined through the primary keys of the tables or through a custom join path. In order for the primary key join to work, the primary keys of the table to be joined need to be included in the primary keys of the base table. You can also add a filter for each joined table.
Time filter
Creation date filter: A filter on a data column that will be used in both full and delta loads. This filter will be combined with the "Filter Statement" under "Additional Filters" with an AND condition. So both conditions must be met.
Change date filter: A filter on a date column that automatically looks for the maximum date in the existing table and sets a filter to only extract data newer than this maximum date. This filter will be combined with the "Delta Filter Statement" under "Additional Filters" with an AND condition.
Additional filters
Filter statement: Using SQL syntax, specify which rows will be extracted, e.g. COLUMN1 > 5.
Delta filter: Using SQL syntax, specify which additional filters should be applied when the job executes a delta load. This filter statement is combined with the normal filter with the logical AND operator.
Debug mode
Once enabled, the debug mode provides detailed log information for the data extraction job and will be displayed in the execution logs. This allows for more transparency and easier troubleshooting. This mode is active for three days and the logs created are then deleted.
Managing existing extraction tasks
You can manage existing extraction tasks by clicking Options.
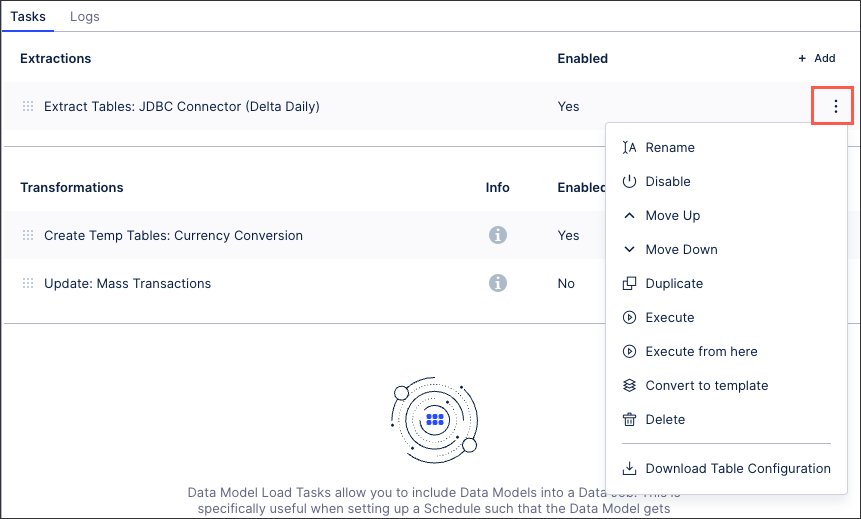 |
You have the following options here:
Rename: Update the name of the extraction task.
Enable / disable: Control whether the extraction task should be enabled or disabled for executions.
Move up / down: Change the order in which this task is performed in a full execution.
Duplicate: Create a copy of the extraction task in the existing data job.
Execute: This allows you to manually execute just this task on demand. For more information about executing data jobs, see: Executing data jobs.
Execute from here: This allows you to manually execute this and all following tasks on demand. For more information about executing data jobs, see: Executing data jobs.
Convert to template /copy to regular task: The task becomes a template and can be added to other data jobs or used to extend the template. If the task is already a template, you can create a regular task from it. For more information about task templates, see: Creating task templates.
Delete: This deletes the task and all associated content, with no recovery possible.
Download table configuration: This gives you offline access to a zipped file containing any relevant Excel workbook copies of your table configuration.