Before getting started with Duplicate Invoice Checker
Prerequisites
Note
The Duplicate Invoice Checker is purpose-built for SAP ECC and works out-of-the-box with the Celonis SAP ECC Accounts Payable Connector and a standard, full cloud Celonis Platform setup. Any infrastructure, source system or data model deviations require app customizations and are not covered by the standard app.
First and foremost, it is necessary to have an advanced understanding of the following concepts to ensure a smooth installation. If not, please complete the training on these topics by visiting the Celonis Academy:
Studio (i.e., concepts like variables or extensions)
Views
Knowledge Models
Skills
Data Integration
Data Models
Please create a ticket through the Support portal to ensure that the following backend flags are enabled for a given team:
Studio - Apps (Knowledge Models, Business Views, Skills)
Celonis: Machine Learning Sensor
Celonis: Celonis Smart Sensor
Celonis: Create Task
Celonis: Update Augmented Attribute
Algorithm compatible with package version 2.X.
Important
Please allow a minimum of three business days to complete the activation. Activating the algorithm compatible with package version 2.X affects all ML Sensors within a given Celonis Platform team. Please make sure that the PQL in all packages with an active ML Sensor has been migrated.
For detailed information, see Release Notes January 2023.
To run the ML Sensor and to yield results from the algorithm, the data model should contain at a minimum the following information:
Invoice value (integer/floating-point format)
Document date (date format)
Invoice reference (string format)
Vendor name (string format)
Event log or activity table
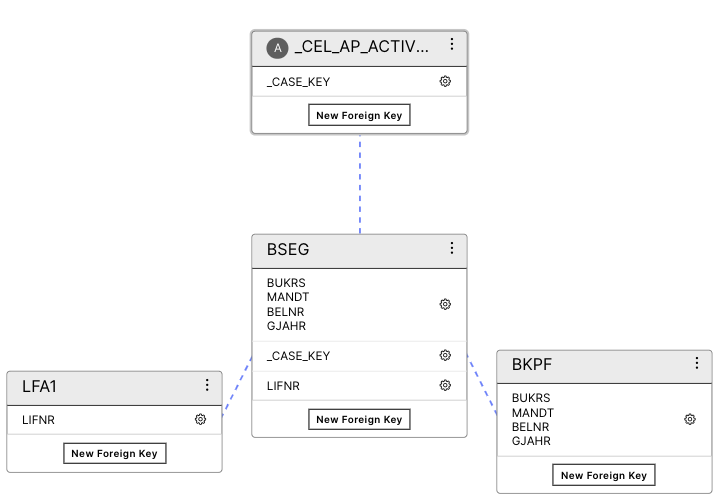
The app expects the following tables:
BSEG (Document line table - Case table)
BKPF (Document header table)
LFA1 (Vendor table)
_CEL_AP_ACTIVITIES (Activity table) with activities (“Create Credit Memo”, “Reverse Invoice”)
Apart from invoices (31 posting key), it is recommended to also include credit memos (21 posting key) in the case table to be able to identify invoice-unrelated credit memos. This reduces the number of potential false duplicates.
Note
A single data model can only be used with one Duplicate Checking package or the Accounts Payable Starter Kit. If there is more than one Duplicate Checking package or Accounts Payable Starter Kit pointed to the same data model, they will fail with an error saying that there is already another app on that data model.
The use case
Detecting duplicate invoices in the Accounts Payable process prevents unnecessary payments to vendors. For duplicate invoices already paid, there is the possibility to reclaim previous payments from vendors. The goal is to identify duplicates as early as possible before they are being paid to be able to set a payment block or reverse the invoice. Today, this results in a lot of manual effort.
The focus of the Duplicate Invoice Checker is facilitating this process by detecting duplicates that have slipped through the ERP controls. The app achieves this by using a Celonis fuzzy matching algorithm that expands beyond traditional exact matches computed by ERP systems. After having analyzed the invoice data, the algorithm groups invoices together that are suspected to be duplicates based on different matching patterns. These patterns are based on the following four dimensions: Invoice value, document date, invoice reference and vendor name.
Once the groups have been computed, the app allows users to review the potential duplicates, provide feedback whether it is a duplicate or not, and then take action accordingly.
Components and data flow
The Duplicate Invoice Checker works across three layers in the Celonis Platform: Definition layer, execution layer and data layer. It is essential to understand how the data flows across the different layers and the purpose of each component in order to be able to refine and debug the application.
Definition layer: This layer stores the business logic and common understanding of the application in the form of filters, KPIs, attributes, records, etc.
Execution layer: The execution layer is where the work of the app is done or visualized. It always uses the definition layer to retrieve the right data from the data layer.
Data layer: The data layer is where the data is stored and ready to be used at the other layers.
The following graph depicts the interaction between the different layers and components:
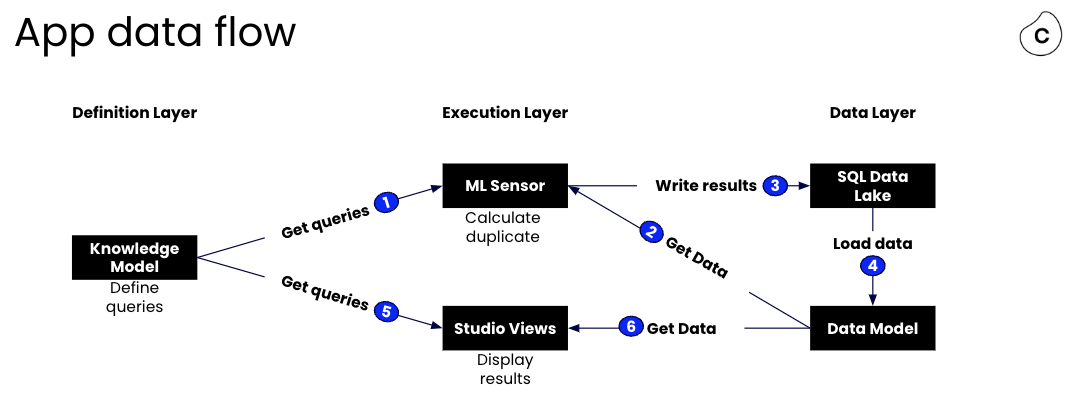
There are some differences in the data flow in different versions of the Duplicate Invoice Checker.
The ML Sensor gets the definitions from the knowledge model (e.g. filters and attribute definitions)
The ML Sensor queries the data from the data model (given that the data model has been loaded).
The algorithm computes groups of potential duplicate invoices based on different matching patterns, and then writes back the results into a table (name: “DUPLICATE_INVOICES + package-key + knowledge-model-key”) in the Data Pool of the data model, using the alias “DUPLICATE_INVOICES”. This is done via an upsert based on the primary key of the document, meaning that if the table exists, already existing rows are updated and non-existing rows added. If the table does not exist, it gets created from scratch.
A dedicated Data Job (name “GROUPS_DUPLICATE_INVOICES + package-key + knowledge-model-key”) is automatically created in the Data Pool of the data model to create a table (view) with group level information of the “DUPLICATE_INVOICES” entries, using the alias “DUPLICATE_GROUP_INVOICES”. During the first run, the two tables are added and subsequently loaded to the data model.
The Studio View takes the definitions from the knowledge model.
And queries the data from the data model based on these definitions. After the next data extraction, the cycle starts again.
The ML Sensor gets the definitions from the knowledge model (e.g. filters and attribute definitions)
The ML Sensor queries the data from the data model (given that the data model has been loaded).
The algorithm computes groups of potential duplicate invoices based on different matching patterns and then writes back the results into a table (name: “DUPLICATE_INVOICES + package-key + knowledge-model-key”) in the Data Pool of the data model, with the alias “DUPLICATE_INVOICES”. This is done via an append, meaning that rows are added to the table. If the table does not exist, it gets created from scratch.
A dedicated Data Job (name “GROUPS_DUPLICATE_INVOICES + package-key + knowledge-model-key”) is automatically created in the Data Pool of the data model to create a table (view) with group level information of the “DUPLICATE_INVOICES” entries, using the alias “DUPLICATE_GROUP_INVOICES”. During the first run, the two tables are added and subsequently loaded to the data model.
A dedicated Data Job (name “DISTINCT_DUPLICATE_INVOICES + package-key + knowledge-model-key”) is automatically created in the Data Pool of the data model to create a table (view) with distinct invoice keys of the “DUPLICATE_INVOICES” entries, using the alias “DISTINCT_INVOICES”. This table serves as a link between the invoice record table (“BSEG”) and the result table (“DUPLICATE_INVOICES”). During the first run, the three tables are added and subsequently loaded to the data model.
A table, with the name “DC_RUNS + package-key + knowledge-model-key”, is automatically created or appended in the Data Pool of the data model. This table stores metadata about each Duplicate Checking run (e.g. algorithm version).
If the record identifier used in the ML Sensor is changed after the “DUPLICATE_INVOICES” table has been created, a table, with the name “DC_ARCHIVE_TABLE + package-key + knowledge-model-key”, is automatically created or appended in the Data Pool of the data model. It archives the results of the “DUPLICATE_INVOICES” table since the table schema has changed.
If there are entries for the augmented attribute “STATUS”, a table, with the name “DUPLICATE_GROUP_AUGMENTED_STATUS”, is automatically created or upserted in the Data Pool of the data model. It stores the state of the augmented attribute “STATUS” during the time of the last Duplicate Checking run.
The Studio View takes the definitions from the knowledge model.
And queries the data from the data model based on these definitions. After the next data extraction, the cycle starts again.
As seen from the steps above, the data flow is always linear. For example, the ML Sensor cannot work correctly if the document date is not defined in the knowledge model or if the definition in the knowledge model does not return the correct data from the data model. It is therefore recommended to always check the input component in order to make the following component work.
While the app itself starts with the ML Sensor, it is recommended to to always start any debugging at the data layer and work up through the definition layer over to the execution layer. For instance: Is there an invoice line, invoice header and vendor table in the data model?
The algorithm
The algorithm is at the heart of the Duplicate Invoice Checker. It groups invoices together that are suspected to be duplicates based on different matching patterns (matching stage). With version 2.X, the algorithm now also calculates a confidence score for each identified group using Machine Learning (ranking stage).
At a high level, the algorithm works as follows:
Every time new invoices are loaded into the connected data model, the algorithm compares them against the invoice backlog. Important here is that only new (unchecked) documents are checked against other new (unchecked) documents as well as against old (already checked) documents. Old (already checked) documents are not checked against old (already checked) documents.
In the standard setup, the comparison is performed on the four invoice fields as defined in the knowledge model: Vendor Name "INVOICE_VENDOR_NAME", Invoice Value "INVOICE_VALUE", Invoice Reference "INVOICE_REFERENCE" and Document Date "INVOICE_DATE".
Fuzzy matching logic flags and groups invoices based on different patterns (matching stage).
Once a group has been identified, a confidence score is calculated that predicts the probability of the group containing a true duplicate (ranking stage). This score allows users to sort or filter the results in the Action View in order to focus on the right groups and to identify duplicates faster.
The algorithm excludes reversed documents from the result set based on the activities in the data model via the "INVOICE_REVERSAL_FLAG".
Filters defined in the ML Sensor reduce the scope of documents checked by the algorithm.
Filters defined in the Action View can exclude certain groups from being displayed, reducing the number of potential false positives.