Data connection endpoints (OData API)
When configuring your data connection you must define the API endpoints for your source system. This includes selecting your API type, configuring your requests, responses, and headers, and optionally managing your error handling.
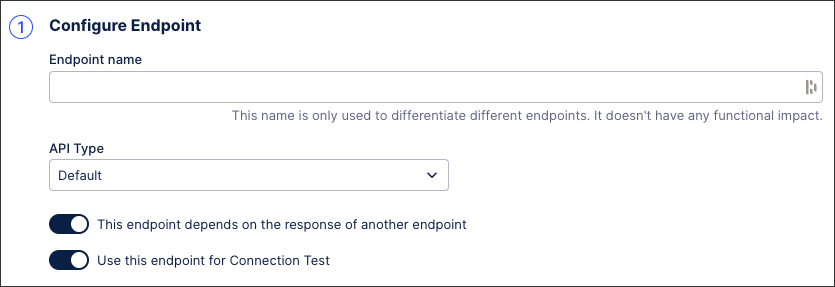
Configuring endpoints
The first stage of configuring your API endpoints is to select the API type. With the Celonis Platform, you can use three API types:
Default: Configure your own API.
OData V2: This allows you to apply filtering in the extraction configuration without defining request parameters. All applied filters will be natively translated into the OData V2 syntax for the request.
OData V4: This allows you to apply filtering in the Extraction configuration without defining request parameters. All applied filters will be natively translated into the OData V4 syntax for the request. Filters on datetime columns must be specified using the UTC timezone.
You can also select whether this endpoint depends of the response of another endpoint - when selected, the dependencies configuration panel is displayed. For more information, see: Configuring dependencies (optional).
 |
Configuring dependencies (optional)
This endpoint will be requested for every unique "Dependency.depends-on-column" value extracted after the extraction of "DEPENDS-ON-ENDPOINT" endpoint. In order to make a request for this endpoint, the placeholder you define in your url or request parameter will be replaced with the actual value of "Dependency.depends-on-column".
You can define dependency in your request in two different ways.
Define dependency in the url: You can use the column you selected with the following syntax "/your/api/{Dependency.depends-on-column}/data"
Define dependency in a request parameter: You can define request parameter where the static value of the parameter is {Dependency.depends-on-column}
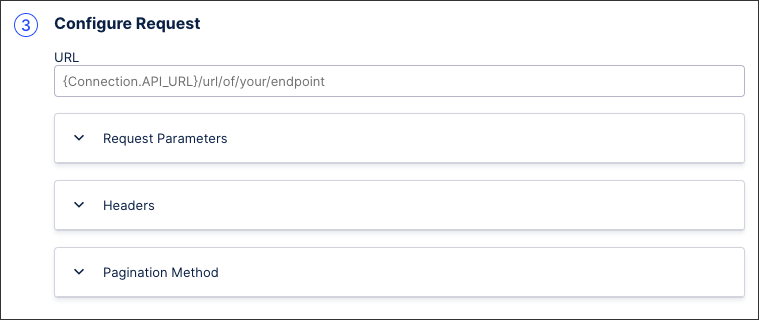
Configuring requests
The request URL defines the API endpoint that is called and can be identified in your source system’s API documentation. It always starts with the connection parameter, configured as {Connection.API_URL}.
You then have the following options:
Request parameter: Add request parameters to apply filters to your API requests, such as the last creation or updated date filters.
Request header: This is done via defining a key-value pair. For example: define Accept as key and application/json as value for the API response to be returned as json.
Pagination method: To fetch data from all pages when extracting, you must select the pagination mechanism used by your source system's API.
For more information about configuring request parameters, see: Configuring request parameters.
 |
Configuring responses
After configuring the API request, you can also configure the response. To define the response structure and content, you have two options:
Example JSON response: Copy and paste a JSON response example from the API documentation of your source system.
Sample a response: If you've already established a data connection with your source system, you can copy a sample response directly from that.
Based on the JSON response copied, the extractor builder automatically creates a table structure including all columns, data types and nested objects. You can configure this table in the following ways:
Multiple response roots: If your JSON response has multiple response roots, you can specify which root you want to extract via the dropdown.
Define primary keys: If you define a primary key for a parent table, the primary key will automatically be created as a foreign key column in its nested tables if they exist. The key will also be used as default primary keys in the extraction configuration.
Adjusting and deleting table elements: You can delete elements from the created table structure by deleting the respective key value pair from the JSON response. Elements you remove here will not be extracted.
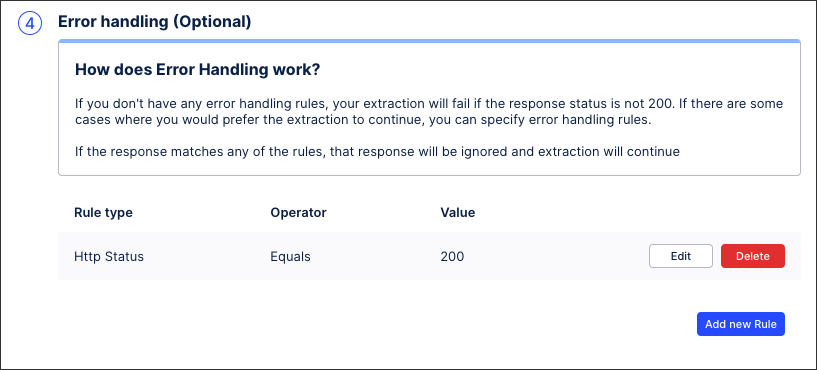
Managing your error handling (optional)
If you don't have any error handling rules, your extraction will fail if the response status is not 200. If there are some cases where you would prefer the extraction to continue, you can specify error handling rules. If the response matches any of the rules, that response will be ignored and extraction will continue.
 |