Versioning of Data Pools
New data integration content available
You're currently viewing a data integration topic that has been replaced and will eventually be removed from our documentation.
For the latest data integration content, see: Data Integration.
Purpose
For a development process, such as setting up Data Pools, maintaining and innovating on Extractions or Transformations, it is important to track changes especially if multiple Data Engineers are involved. To guarantee that everyone who is working on a Data Pool knows what has been changed and when, the Data Pool Versioning enables you to easily trace changes in your Data Pools. By backing up stable versions and being able to jump back to them if any issues are detected in the current setup, the Data Pool Versioning can additionally increase the health of productive data pipelines.
Moreover, with the Data Pool Versioning a new publishing workflow of Data Pools is introduced that allows you to clearly separate the development and productive environment. Versions of Data Pools can be copied easily from one Data Pool into another which allows larger teams to set up a more scaleable software development lifecycle for their data pipelines.
How does it work?
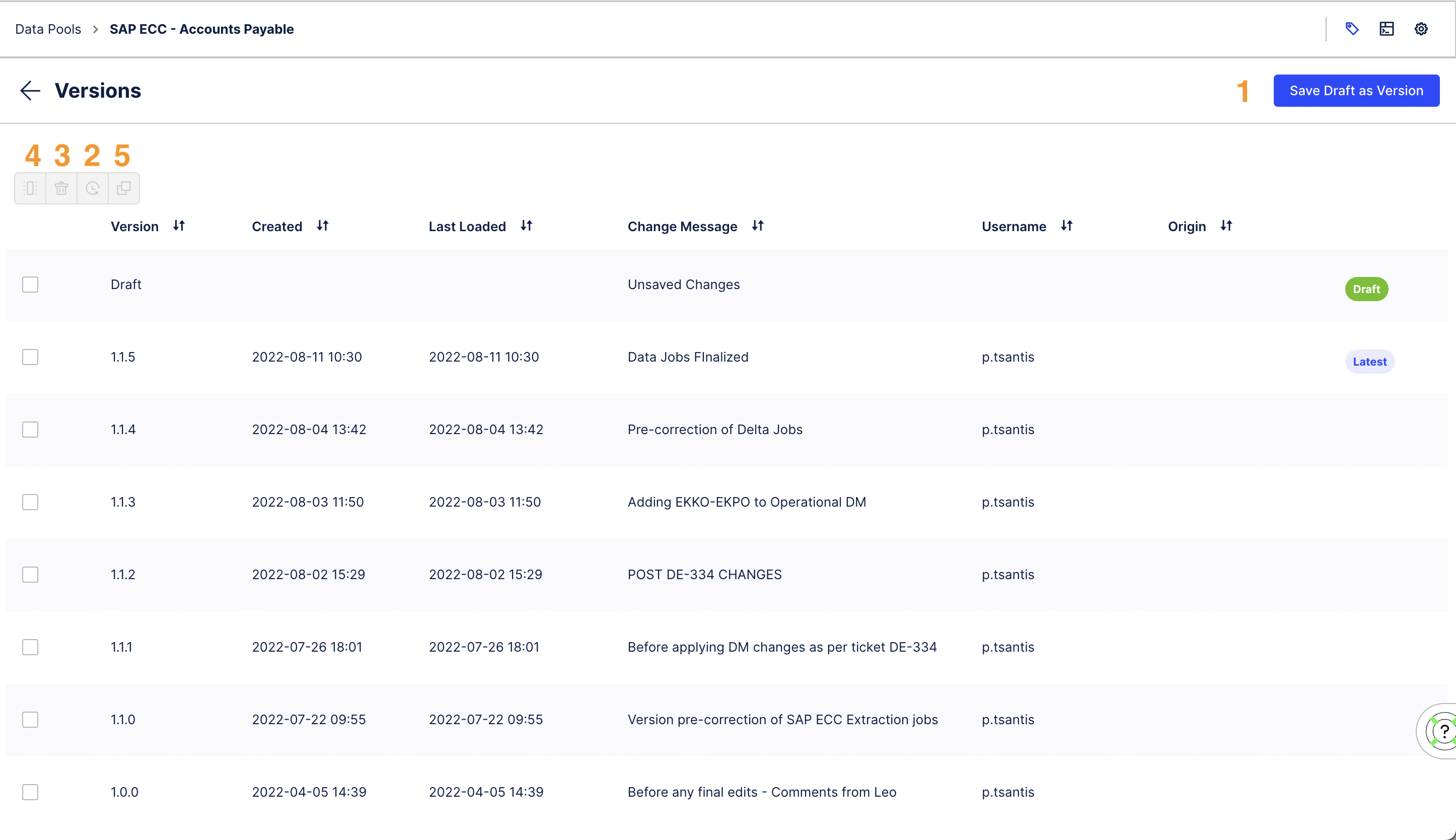 |
Save Draft as Version (1)
When you get started the versions table will contain only one draft row. This row reflects the current as-is state of the Data Pool. Click on the button 'Save Draft As Version' to save a new version. In the pop up you can decide on the severity of your changes (Patch, Minor, Major) which will be directly reflected in the version number. In addition, you can add a change message to describe what was changed. A saved version cannot be changed. After saving a version the draft row disappears until new changes are made to the Data Pool.
A Data Pool Version saves all configurations for:
Data Jobs including all Transformations and Extractions
Data Models (excl. name mappings)
Data Pool Parameters
Task Templates
Schedules
Replication Cockpit configuration (including Extractions and Transformations)
Not yet included in a version are the Replication Cockpit, the Extractor Builder, and the Streaming Cockpit.
Data Connections/ Data Transfer configurations, data itself, logs, permissions, and alerts/ notifications are intended to be not saved in a version due to security and privacy reasons.
Load a version (2)
The "Latest" tag indicates which version was last loaded into the Data Pool. If there is no draft row, the loaded version is visible in the Data Pool and all upcoming executions run on it. If changes are made to the loaded version it automatically counts as new draft, which can then be saved again in a new version. In this case all upcoming executions run on the draft.
To load a version select the version you would like to load and click the load icon on the actions toolbar on the top left of the table. If you load a version meanwhile you have a draft row, i.e. unsaved changes, these changes will be deleted. This cannot be undone.
Delete a version (3)
Select the version you would like to delete and click the delete icon on the actions toolbar on the top left of the table. This cannot be undone.
There is a limit of maximum 100 versions per Data Pool. No Versions will be deleted automatically, but if the limit is reached you need to delete a Version first before you can save a new one.
Compare versions against each other (4)
To compare two versions with each other select the two versions in the table and click the compare icon on the actions toolbar on the top left of the table. A pop-up will show you all the differences between the two versions. If you like to see what changes have been made to the last loaded version you can compare the last loaded version to the draft row.
Copy a version to another Data Pool (5)
A Data Pool Version can be copied into another Data Pool, even if the other pool is in another team. To be able to do so the user needs to have admin rights on the source and the target Data Pool.
When copying a Data Pool Version you are asked to:
Select the team that contains the Data Pool you want to copy the version to. It can be also the same team in which you are logged in.
Select the Data Pool you want to copy the version to.
Map the source data connections with existing target data connections. This step is needed since versions do not contain data connections and Data Jobs need to be assigned to a data connection. You can also map e.g. two source data connections to the same target data connection. This step cannot be skipped.
Match the source Data Models with the currently existing Data Models in the target Data Pool. Data Models are part of versions, but Data Models are the interface to all other Celonis Platform products. The matching is used to preserve the Data Model IDs between versions to be able to keep links to analyses or views and Data Model subscriptions. For example is an analyses linked to a Data Model via the Data Model ID. A new version from a different Data Pool would have a different Data Model ID. To not loose these links between Data Models and e.g. analyses the matching ensures that the same links between the new Data Model and Celonis Platform objects are created as it is for the in the target pool existing Data Model. Since these IDs need to be unique you cannot match two Data Models of the source Data Pool to the same Data Model in the target Data Pool. All unmatched Data Models from the version are just created with new IDs, wherefore you can skip this step if you like.
Match Data Jobs with the currently existing Data Jobs in the target Data Pool. Data Jobs are part of a version. The matching is used to preserve the Data Job IDs between versions to be able to keep attached Data Job Alerts. Since these IDs need to be unique you cannot match two Data Jobs of the source Data Pool to the same Data Job in the target Data Pool. If you skip a matching or the entire matching, the alerts are not preserved between versions in the target Data Pool. You can skip this step if you do not need to preserve Data Job Alerts in the target Data Pool.
Decide whether the new version should just be added to the Data Pool as new Data Pool Version or if it should also be loaded directly (see 2). If you decide to directly load the version all changes that are not saved in a version in the target Data Pool (changes depicted in the draft row) will be lost. If you don't have a version yet in the target Data Pool, then all current configurations in the target Data Pool will be overwritten and deleted. This cannot be undone.
Click copy. You can navigate now to the target Data Pool, where you can find the just copied version in the versions table. The "Origin" column contains the name of the data pool from which the version was copied. If this column is empty, the version was created in the data pool itself.