Data Jobs
New data integration content available
You're currently viewing a data integration topic that has been replaced and will eventually be removed from our documentation.
For the latest data integration content, see: Data Integration.
Quick Start: What is a Data Job?
Data Jobs are used to extract data from different connected system and transform the data to prepare it for process mining.
You will set up Data Jobs after you've created a Data Connection (e.g. to Salesforce, Oracle, SAP etc. ) and can continue afterwards with setting up the Data Models.
Data Jobs are usually set up by Data Engineers and do not need to be adapted afterwards by Business Analysts or Viewers.
Data Job Configuration
Creating a Data Job
In order to create a new Data Job you need to click on "+ Add a Data Job" in the "Data Job" section. This will open a modal where you specify a unique name among the Data Pool and specify the Data Connection it should relate to. There are two distinct types of Data Jobs:
Data Connection Jobs
Global Jobs
Data Connection Jobs are bound to a specific Data Connection (which can be changed), whereas Global Jobs only transform existing data, e.g. unifying data from different Data Connections into one or multiple joint tables.
Warning
Global Jobs cannot be transformed into Data Connection Jobs or vice versa. Since Global Jobs are not bound to a Data Connection they can only contain Transformations and no Extractions.
Tip
Create a Data Connection Job at first. Global jobs (those without a Data Connection) are only needed if you would like to unify data from different systems.
Actions on a Data Job
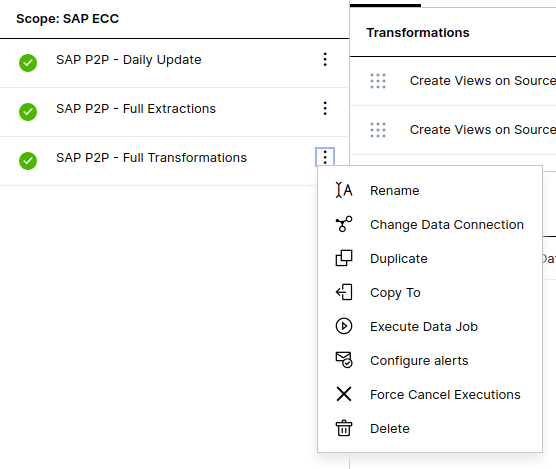
The following actions can be performed on a job by clicking on the context menu to the right of the job name:
Rename: Must be unique among the jobs in one data pool (also across data connections)
Change Data Connection: This is only available for data connection jobs, not for global jobs. You need to make sure that the tables that the extractions define and the columns used for filtering etc. are also available in the new data connection.
Duplicate: Copies the job along with all tasks and their parameters. The status and the logs are not copied.
Copy to: Copies the job into another pool on the same or a different team on the same cluster including all extractions, transformations, local parameters and templates. Pool parameters, data model loads and job alerts are not copied. The link to a pool parameter is replaced in the target pool by the value of the pool parameter of the source pool. If you copy a job including extractions to a global scope, the extractions are removed.
Execute Data Job: Opens the modal to configure the job execution.
Configure alerts: Subscribes you to alerts of the Data Job.
Force Cancel Executions: Cancels the execution of the data job that is currently running.
Delete: Deletes the job and its tasks.
Actions on a Task
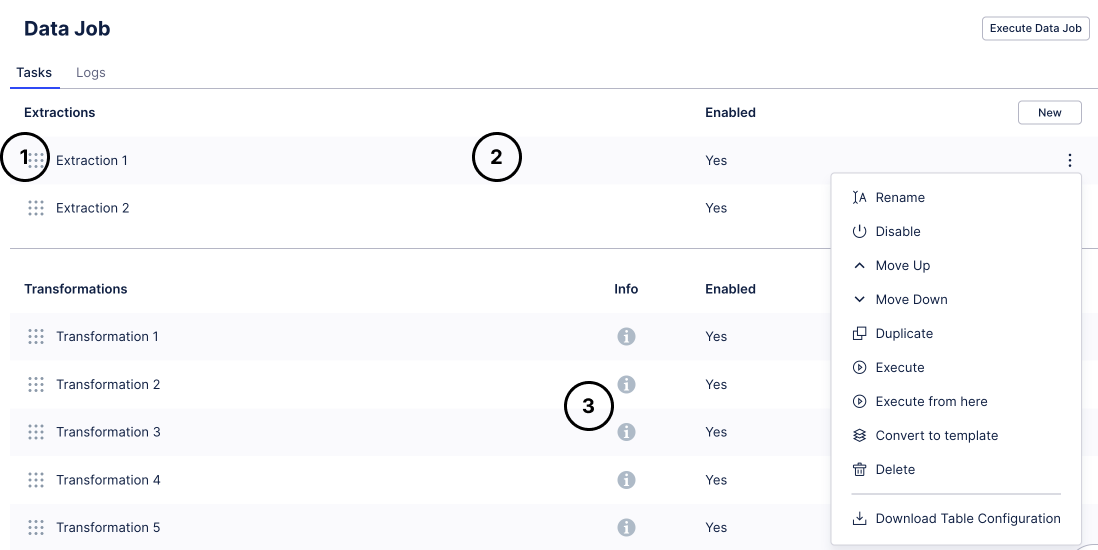
The following actions can be performed on a task:
By dragging on the handle to the left of the task name you can change the order of the tasks which affects the execution. Alternatively, you can use the actions "move up" and "move down" in the context menu.
By clicking on the task between the drag handle and the content menu button, you open the task to modify its contents.
By clicking on the info icon you can display the description of the transformation.
The other actions are available in the context menu on the right:
Rename: Modify the name of a task or the description of a transformation
Enable/Disable: If a task is disabled, it will be hidden in the execution modal and it will not be executed by schedule. The status is shown next to the task name.
Duplicate: Copies the task and adds it right after the base task along with the content and all parameters.
Execute (from here): Opens the execution modal with the respective task pre-selected. When clicking "execute from here" all the following tasks are also pre-selected.
Search: you can search through the content of all Tasks within a Data Job using a free text search.
Convert to template/Copy to regular task: The task becomes a template. Please refer to the Task Template section for details. If the task is already a template, you have the option to create a regular task from it if you can access the content of the template.
Delete: The task and all its contents is deleted.
Data Job Executions
New data integration content available
You're currently viewing a data integration topic that has been replaced and will eventually be removed from our documentation.
For the latest data integration content, see: Data Integration.
After your Data Job and its contained Extractions and Transformations are configured, you can start your first execution. It makes sense to start with merely extracting one table in full mode to verify that the connection is working correctly. Afterwards, the Data Job can be executed completely in a manual way. After it is verified that this works as expected, it is advised to set up a Schedule to automatically execute the Data Job in Delta Mode continuously.
Triggering a Data Job Execution
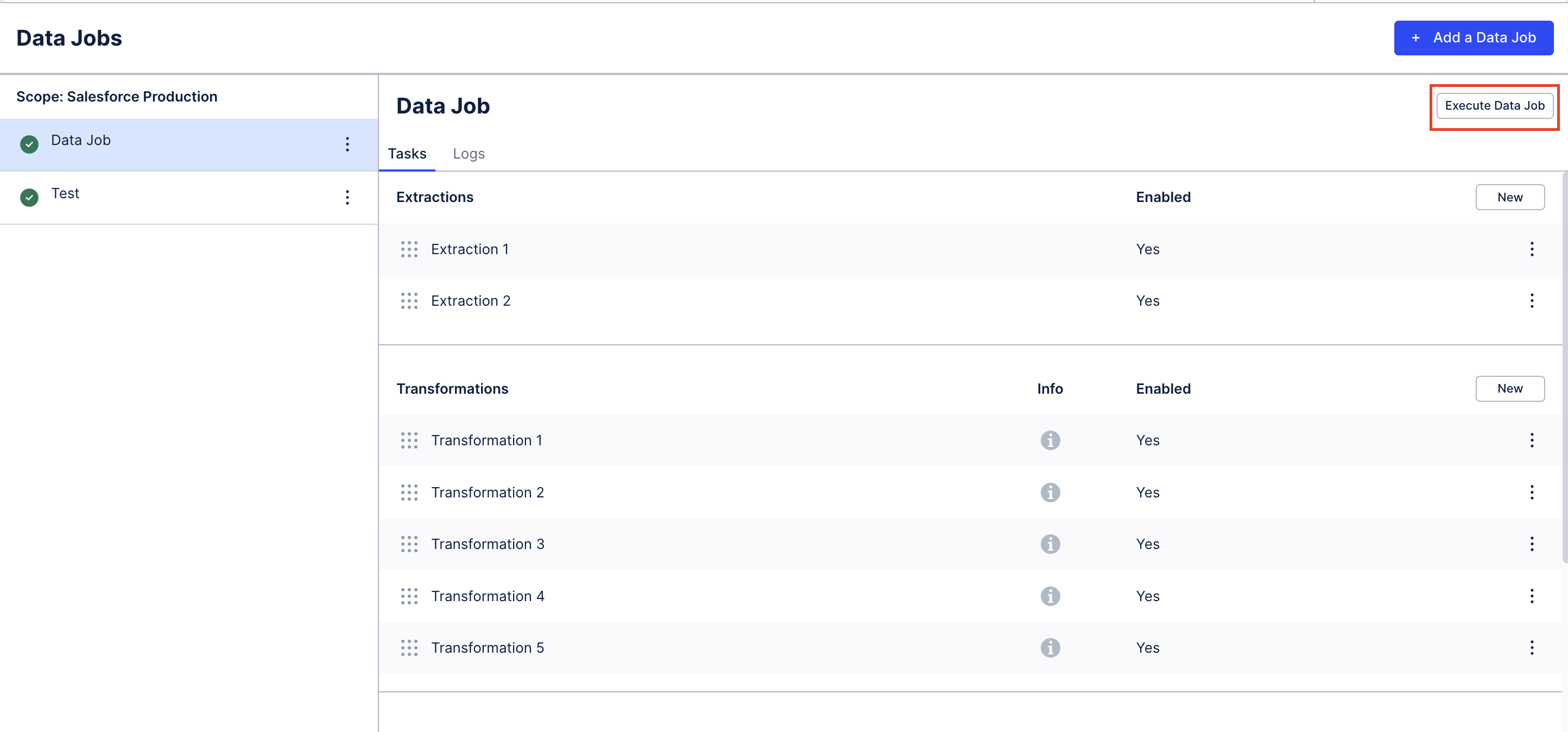 |
You can execute a Data Job manually by selecting the "Execute Data Job" within the Data Job configuration.
Note
The manual execution will open the execution modal which allows you to configure which Tasks of the Data Job should be executed. Please note that the modal only contains Tasks that are enabled. In order to execute disabled Tasks you need to enable them first.
Tip
Instead of executing Data Jobs manually, you can also schedule them to be executed automatically and periodically.
Execution Modal
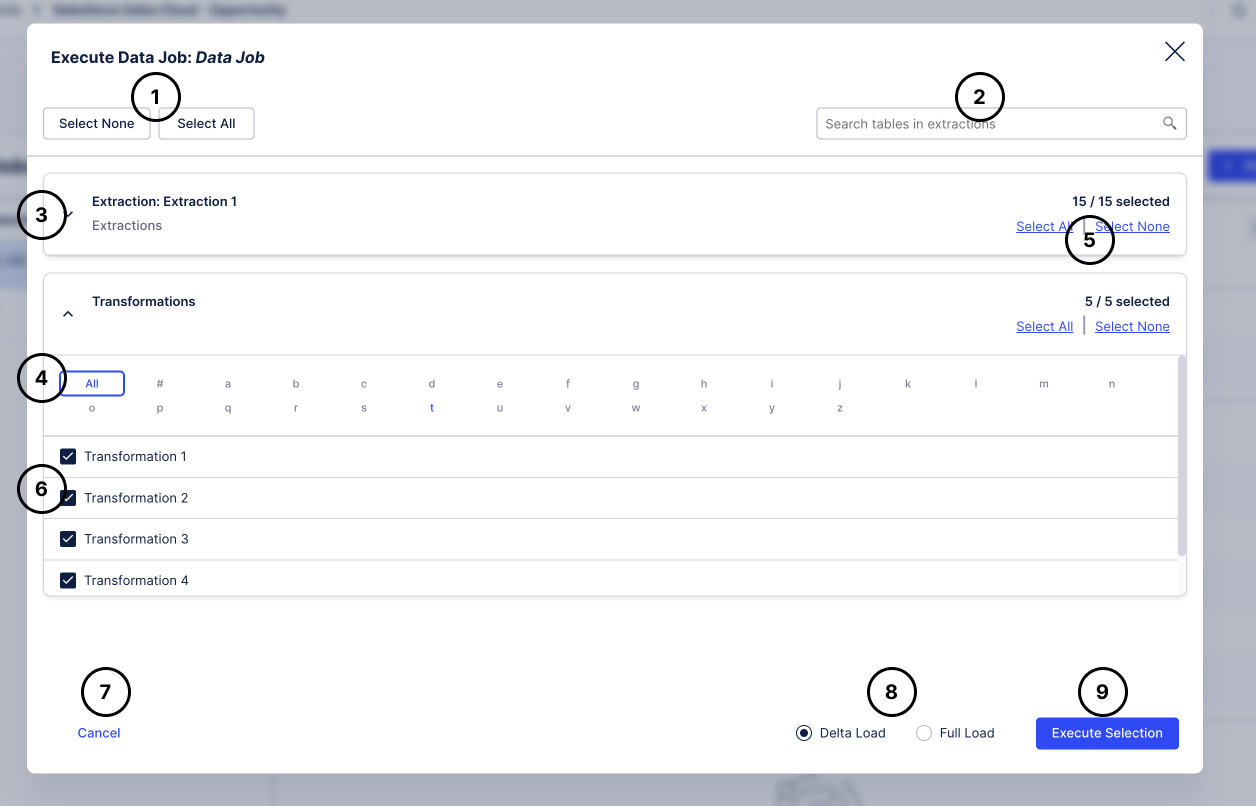 |
Select or deselect all tasks of the Data Job.
Search table names. This will filter the view of extractions to only the ones containing the search term.
Show and hide the list of tables.
Use the alphabetical chooser to only see tables that start with a certain letter.
Select and deselect single tables or (de)select them- Only if an item is selected, the corresponding action will be performed.
Transformations can be expanded as well and transformations can be (de)selected
Cancel to not execute the Data Job.
Choose between a full and a delta load, see below for details.
Execute the selected items. This button is only enabled if at least one task is selected.
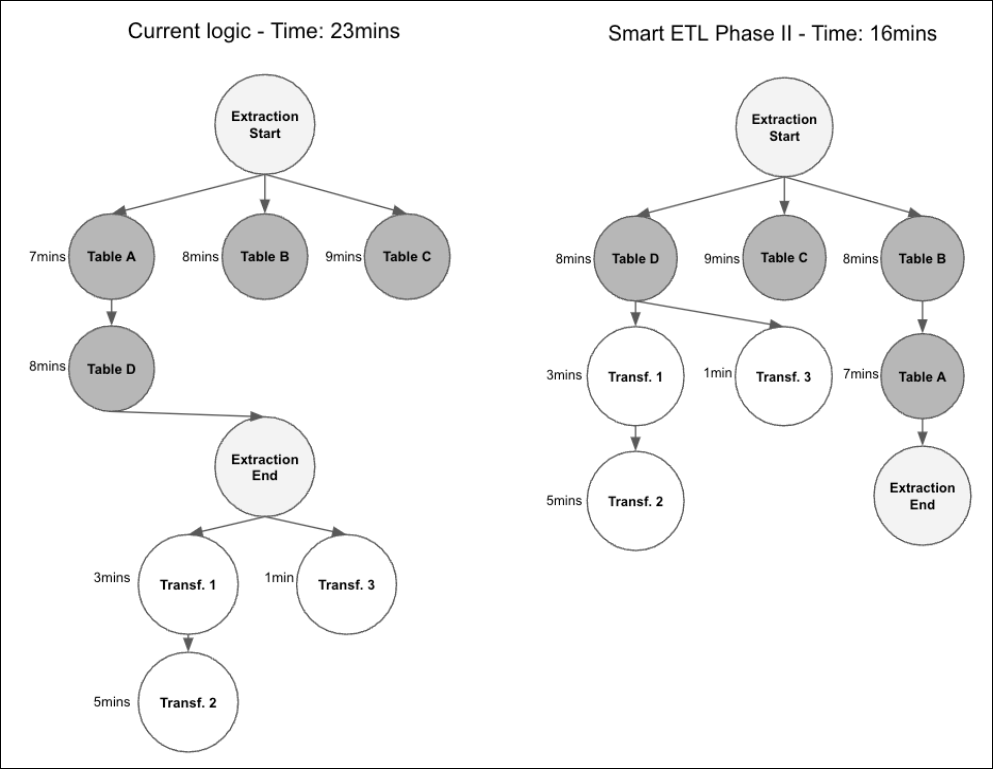
Execution Order - smart ETL
The smart ETL capabilities also include Extractions. This changes the execution order of a Data Job in the following ways:
Before each Data Job execution, the optimal execution order based on the dependencies across all Extraction and all Transformation Tasks in a Data Job is calculated automatically;
Taking into account historical data for Extractions, we automatically optimize the order in which tables get extracted using an internal optimization algorithm. As part of this step, we consider the configuration for the maximum number of tables extracted in parallel, which means never extracting more tables in parallel than configured in the Data Connection;
A DAG (Directed Acyclic Graph) representing the optimal execution order is created automatically in the background;
The DAG is used as a basis to automatically trigger all Extraction and Transformation Tasks based on the optimal execution order. This means once a table has been extracted, we automatically start the related Transformations (while independent tables might still be extracted).
The difference between the current smart ETL logic and the extension to Phase II is displayed in the following graphs:
 |
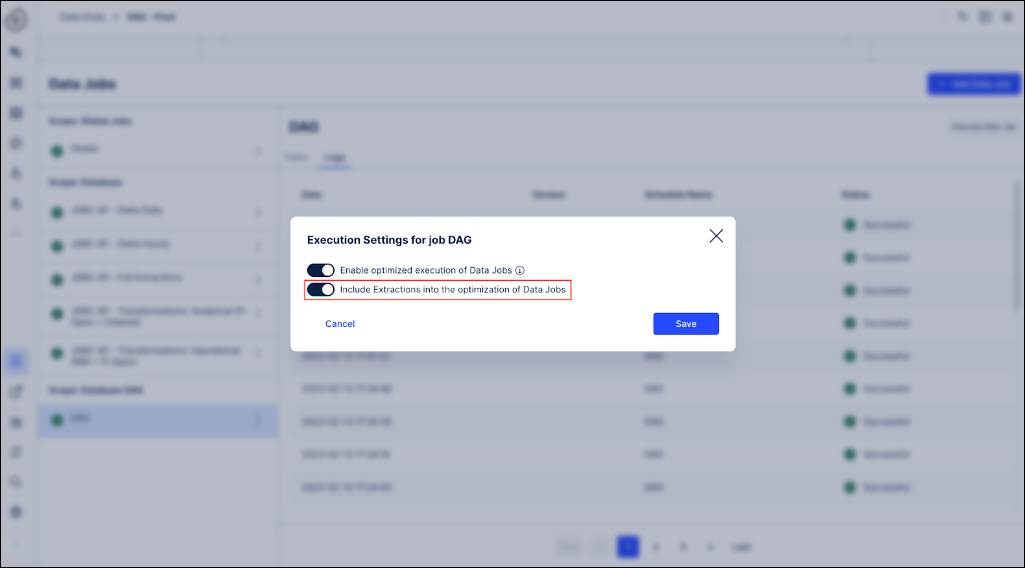
Including Extractions into smart ETL is configured on the Data Job level by going to the three-dot menu, selecting Execution Settings and toggle the Include Extractions into the optimization of Data Jobs option on. This can then be activated or deactivated by users via the UI.
 |
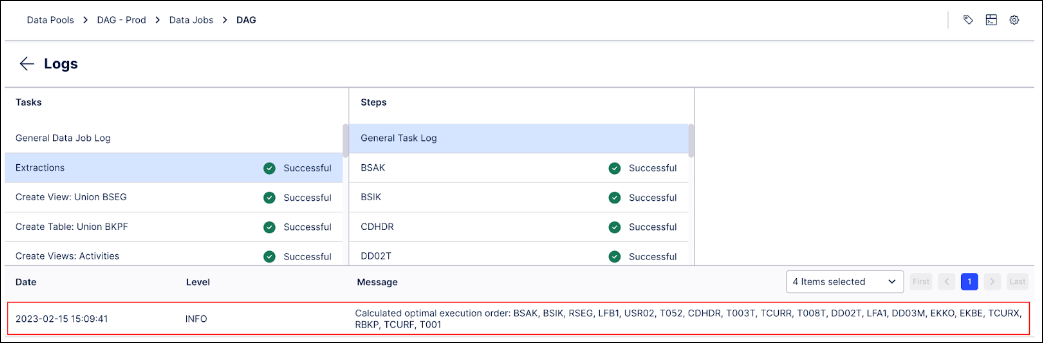
When starting a Data Job with the functionality described above enabled, you will see that Extractions are not running based on the current alphabetical order anymore, but their order will be optimized using an internal algorithm taking historical executions into account. The used order will be recorded in the Logs.
 |
Additionally, certain Transformations will already be started while independent tables still get extracted, meaning Extractions and Transformations will be running in parallel.
This functionality is also summarized as part of a short demo in the video below:
Load Variations
New data integration content available
You're currently viewing a data integration topic that has been replaced and will eventually be removed from our documentation.
For the latest data integration content, see: Data Integration.
Full Load
When you select "Full Load", the tables in the Celonis Platform that have the same name as the ones in the extraction will be deleted and the new data is written to the Celonis Platform. However, the existing data is only deleted after the extraction was successful so you will not lose data unless the extraction finished successfully.
Delta Load
The purpose of delta loading is to reduce the amount of data needed to be transferred between the source system and Celonis Data Integration to enable more frequent reloads.
Important
If the structure of the table has changed, such as columns being added or removed, you can perform an extraction that ignores the metadata changes at the table level. However, if a data type within the table is changed, a Full Load is required to update the table structure.
You should almost always use Delta Loads, especially for large data volumes to reduce both the impact on your Data Connection and the time for the execution. This also allows you to extract data more frequently.
Extraction Filter
The delta load uses a conjunction of the normal filter and the delta filter. Typically, the delta filter field should contain a filter statement that only extracts the newest data which is either not in the Celonis Platform yet or which has been updated since the last Extraction. In order to facilitate specifying this filter, you can use dynamic Task Parameters with the operation type FIND_MAX which query the existing data and generate the maximum of a column. This Dynamic Parameter can then be used to restrict the data volume to only the newest data.
Example: table1 in your system contains the column LAST_CHANGED_DATE which contains the date on which the last change to the row occurred. If you use a dynamic parameter "LastChangedDate" to retrieve the maximum last change date from the existing data you will get the last change date of table1. Then, you can use the following delta filter:
LAST_CHANGED_DATE >= <%= LastChangedDate %>
This filter will retrieve all rows which have been updated after the last change happened.
Update Mechanism
This is the process that is followed to update existing data:
Retrieve the primary key or keys from the extracted data. Which column is a primary key is either taken from the source system or from the extraction configuration if available.
Delete all rows of the existing data table that have the same primary key(s) as the new data.
Insert all rows from the new data into the existing data table.
Actions while an execution is in progress
While a Data Job is running you can view the current status in the Logs tab or in the Execution History. However, you can also modify its configurations without interfering with the current execution. Moreover, you have the possibility to cancel it.
Canceling a Data Job execution
When a Data Job is running, you can cancel its execution by clicking on the "Cancel Execution" button. This will attempt to terminate the running processes of this Data Job both in the application itself as well as in the remote system. If a schedule attempts to execute a Data Job that is already running the Schedule will be skipped automatically.
Modifying a Data Job during execution
You can access and change configurations of all the Tasks of a Data Job and Data Pool Parameters. However, this does only affect future executions of the Data Job. Even if a task is not started yet, the configurations are taken from the point in time when the whole Data Job execution began.