Transformation performance optimization
Every transformation (data preparation and cleaning) in the Celonis Event collection module is executed in the Vertica. For each query submitted to Vertica, the query optimizer assembles a query execution plan, a set of required operations for executing a given query.
When creating transformation queries, every choice has an impact on performance. Understanding the impact gives you the possibility to apply the best practices, avoid anti-patterns and improve overall query performance.
The following guidelines for improving overall query performance should be considered:
Check table statistics
Very easy to implement and significantly improve query performance
Automatically added for all raw tables after extraction
For each temporary table, statistics should be created explicitly by adding the SELECT ANALYZE_STATISTICS('TableName')
Check if all relevant tables have statistics by running the EXPLAIN statement
Check temporary (auxiliary) tables
Content - only necessary data, nothing more
Columns used for joins should be the first columns in create table statement (e.g. MANDT, VBELN, POSNR) or have an explicit ORDER BY clause at the end of the statement
Non-key, custom columns (e.g. Schema_id, source name, etc.) should not be placed at the beginning of the table (affects the sorting and later joins)
ANALYZE_STATISTICS ('TableName') statement added after the create table statement
Check the query statements validity
Avoid SELECT DISTINCT
Make sure that tables are joined properly (to avoid duplication / cartesian product)
Make sure that the entire key is used for joins (e.g., MANDT not ignored)
Join only necessary tables and check if all are really used
Revise the flow of logic, consider other approaches to achieve the same result
Reconsider view/ temp tables
Look for views with big complexity and try replacing them with a temp table (persisted results). It might affect APC and transformation time, but bring stability and overall faster transformation+data model load time
Consider implementing staging tables to enhance data model tables creation and loading
Table statistics are analytical summaries of tables that assist the query optimizer in making better decisions. They provide information about the number of rows or value cardinality in the table.
For tables extracted using Celonis extractor (i.e., “Raw” tables), statistics are automatically updated for each table after the extraction. For custom or temporary tables created within transformations, it is necessary to create statistics explicitly.
To do that, add on the SELECT ANALYZE_STATISTICS ('TABLE_NAME'); after each "Create table" statement, and database will gather statistics in the background.
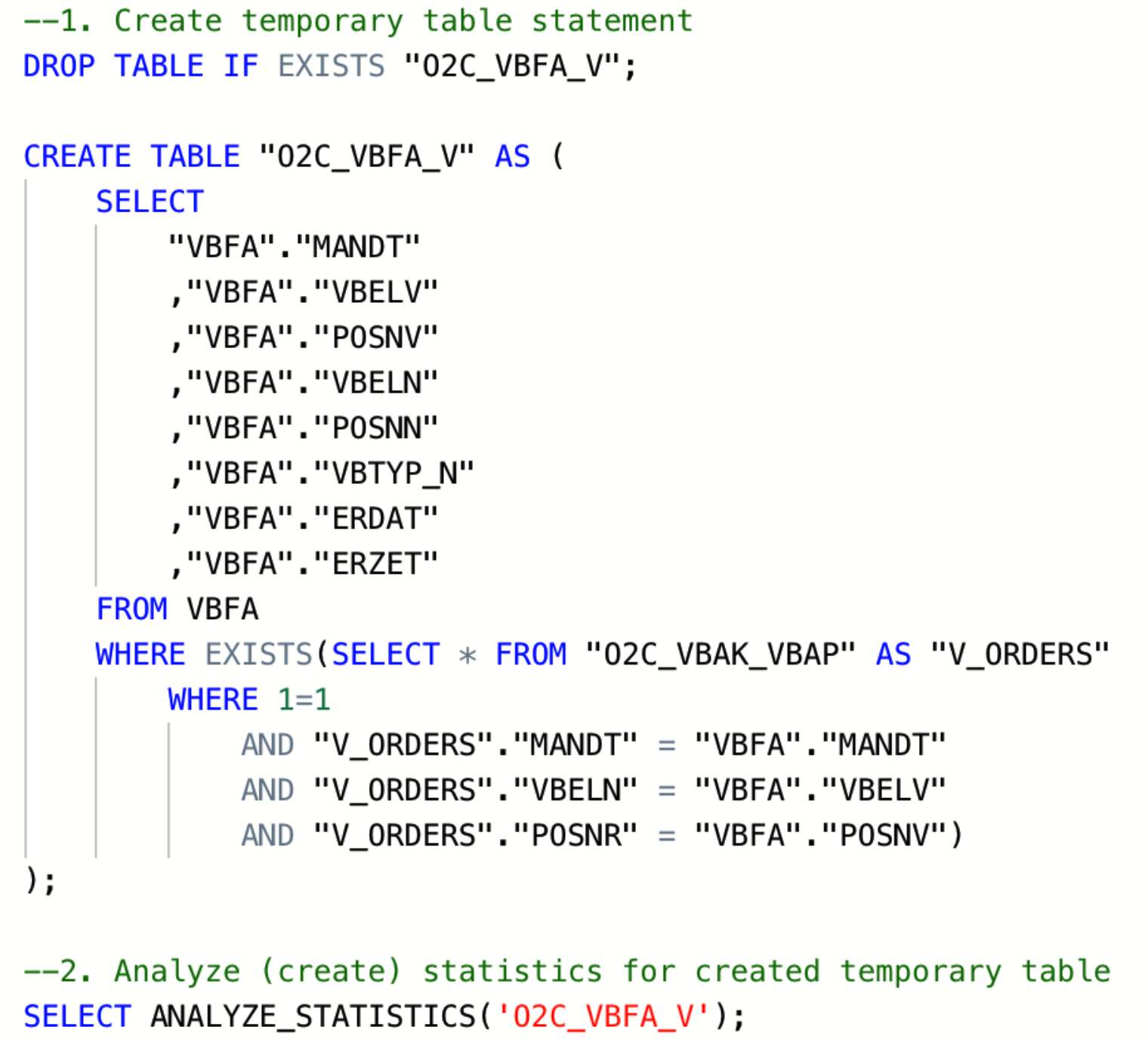 |
Image 1: Example statements for creation of temporary table and statistics
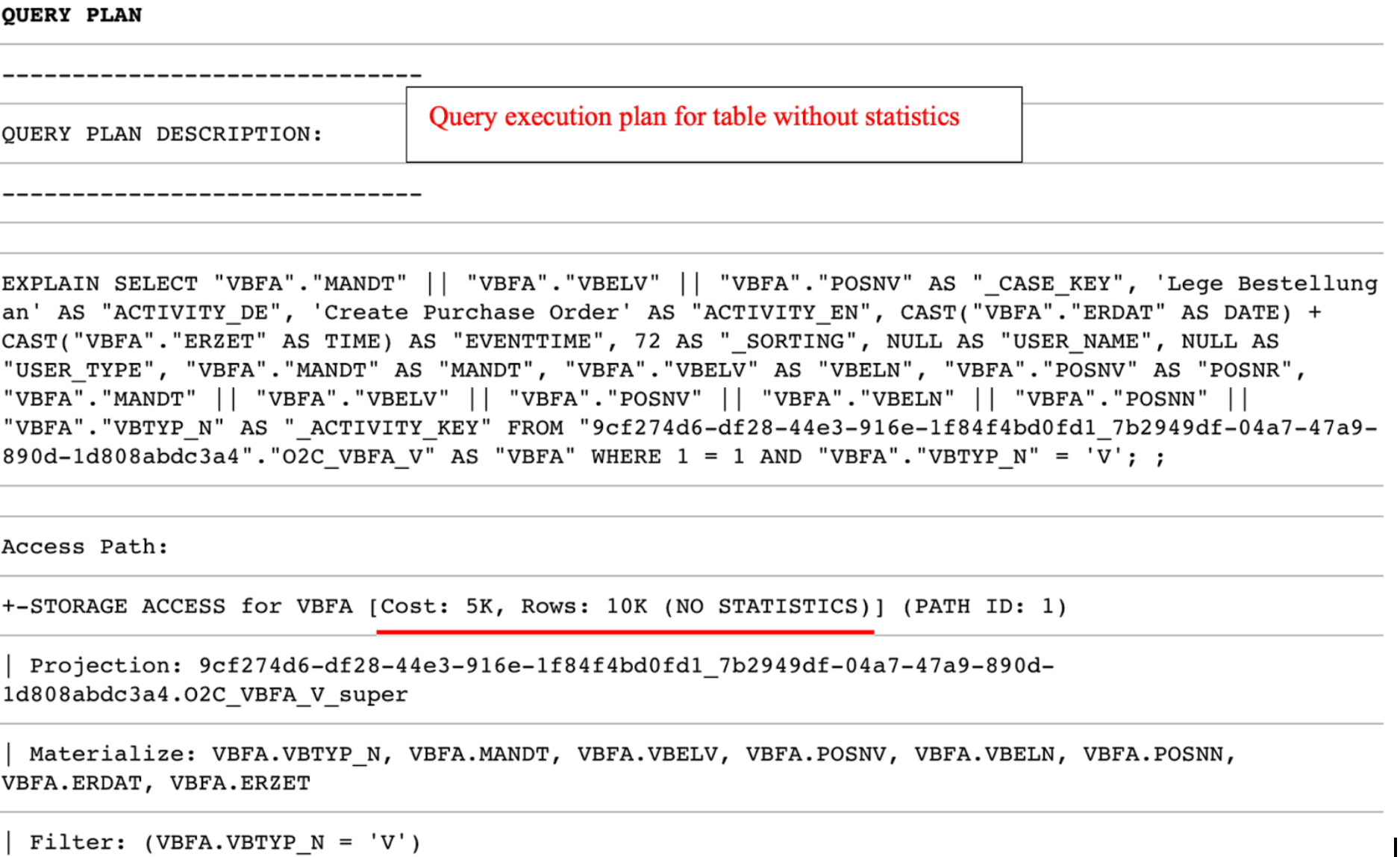
One of the ways to check if all tables in certain queries contain statistics is by reading the query execution plan (EXPLAIN function). If there is “NO STATISTICS” next to a table name, the given table has no statistics. In that case, you need to add the SELECT ANALYZE_STATISTICS (‘TABLE_NAME’); statement after creating this table. Once you ran the statement and generated statistics you can check again using the EXPLAIN function.
Access Path: |
+-STORAGE ACCESS for VBFA [Cost: 798, Rows: 7K (NO STATISTICS)] (PATH ID: 1) |
Example of a query plan where a table “VBFA” does not have statistics
Two scenarios with corresponding query costs are shown in the screenshot below. In the first scenario, the O2C_VBFA_V temporary table is created without statistics, whereas in the second one, statistics have been created for the same table.
 |
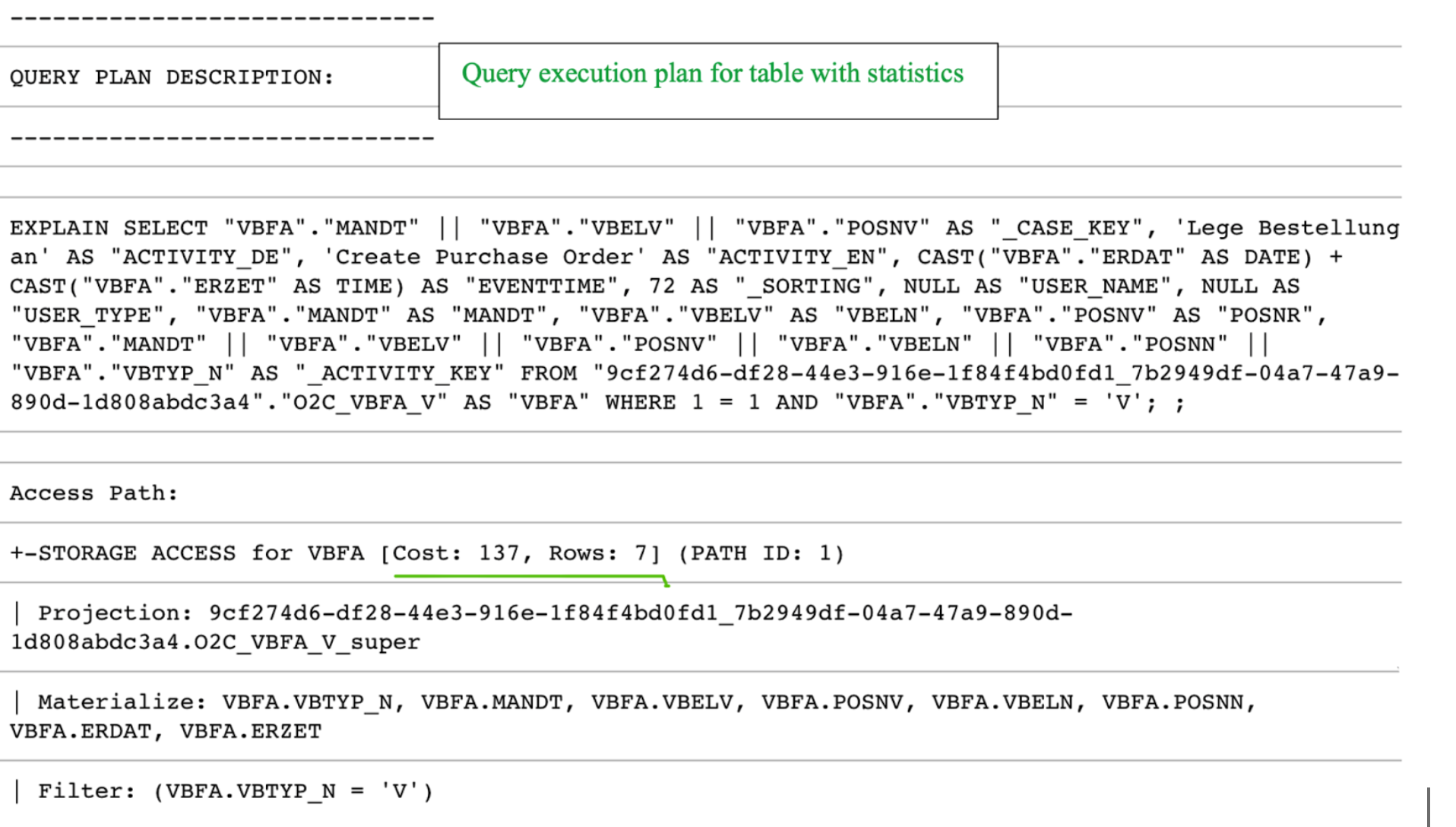 |
Another way to get a list of tables without statistics is by running the following query:
Check for tables without gathered tables statistics
SELECT anchor_table_name AS TableName FROM projections WHERE has_statistics =FALSE ;
If this query returns any result, you should go to transformation script that creates the respective table and add the SELECT ANALYZE_STATISTICS ('TABLE_NAME'); after the "Create table" statement, save the transformation, and database will gather statistics in the background.
Note
Table statistics are crucial for query execution plans with HASH JOINS. They enable the query optimizer to choose the smaller table to produce the HASH table (instead of the bigger one). In most scenarios, this prevents the “inner join did not fit into memory” error.
Table statistics additional read
The temporary, or auxiliary table in this article refers to any table that is created in addition to tables extracted from the source system (raw tables). Those temporary tables (e.g. TMP_VBAP_VBAK, TMP_CDPOS_CDHDR, etc.) are created in the transformation phase.
When creating temporary tables, one should think about the purpose of the table and its relations with other tables (joins). A well-designed temporary table:
Has a clear purpose, for example, to pre-process or join data, filter out irrelevant records, calculate certain columns that will be used later in transformations, etc. The sense of purpose should be validated, to confirm that the creation of temporary tables has a positive impact on overall performance.
Contains only necessary data (e.g. only really required columns and records)
Is sorted by the columns most often used for joins with other tables (e.g., MANDT, VBELN, POSNR). To ensure that, put those columns at the beginning of the create table statement or add an explicit ORDER BY clause at the end of the statement.
Doesn’t contain custom/calculated fields in the first columns. The first columns should be the ones that are used for joins (key columns). If this is not the case, Vertica will have to perform additional operations while running the queries, which will extend execution time.
Contains the Update statistics statement after the create table statement
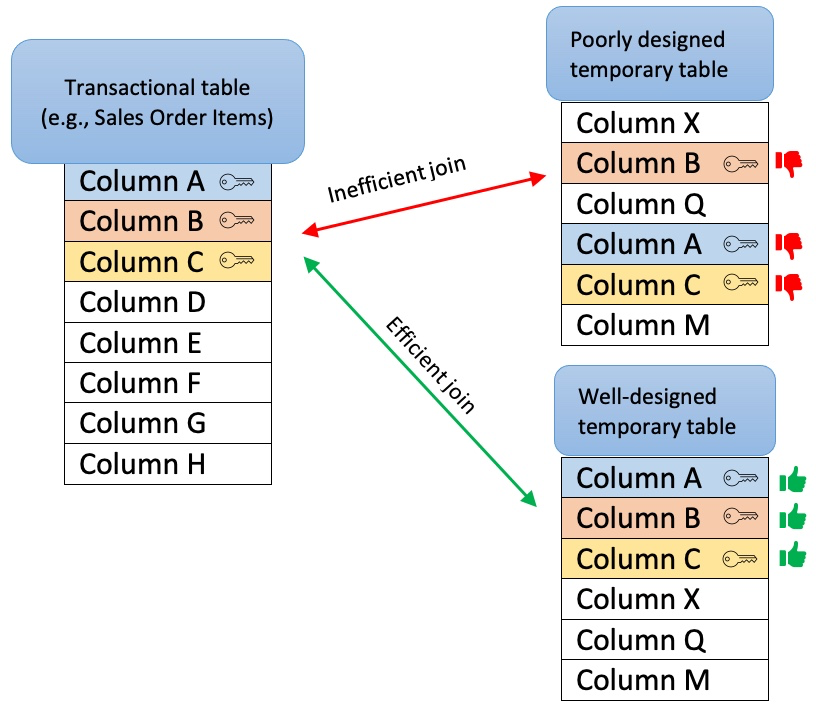 |
 |
Image 2: Inadequately designed temporary table (left) vs Well-designed temporary table (right)
Table Sorting
If the table is not explicitly sorted during the creation statement (by adding an “ORDER BY”), the table (projection) will by default be sorted by the first eight columns in the order defined by the creation statement.
MERGE and HASH joins
Vertica uses one of two algorithms when joining two tables:
Merge join- If both tables are pre-sorted on the join column(s), the optimizer chooses a merge join, which is faster and uses considerably fewer resources.
Hash join - If tables are not sorted on the join column(s), the optimizer chooses a hash join, which consumes more memory because Vertica has to build a sorted hash table in memory before the join. Using the hash join algorithm, Vertica picks one table (i.e. inner table) to build an in-memory hash table on the join column(s). If the table statistics are up to date, the smaller table will be picked as the inner table. In case statistics are not up to date or both tables are so large that neither fits into memory, the query might fail with the “Inner join does not fit in memory” message.
Vertica Projections
Unlike traditional databases that store data in tables, Vertica physically stores table data in projections. For every table, Vertica creates one or more physical projections. This is where the data is stored on disk, in a format optimized for query execution.
Currently, two projections are used in Celonis Platform:
Auto-projection (super projection) created immediately on table creation. It includes all table columns,
If the primary key is known (set up in the table extraction setting), Vertica creates additional projection based on it.
Additional information:
A key difference between a hash join and a merge join lies in how each operation handles memory and sorting:
Hash join: Typically loads one side of the join (often the smaller table or a subset of rows) into memory. This can cause memory pressure and potentially degrade performance for other queries running concurrently.
Merge join: Requires both input tables to be sorted on the join columns. It often performs better than a hash join - especially when joining very large tables, because it avoids the overhead of loading large datasets into memory.
Why force a merge join?
If you examine your query execution plan and notice that two large tables are joined using a hash join, you may be able to improve performance by sorting the data on the join columns so that the optimizer can use a merge join instead. In many cases, forcing a merge join yields better overall performance, but it is advisable to test this approach for your particular workload to confirm any benefits.
Example scenario for a merge join
Suppose your first table is already physically sorted on the ID column (perhaps due to its projection or index), but the second table does not have a compatible projection on Header_ID. Because the second table is not sorted, the optimizer defaults to a hash join.
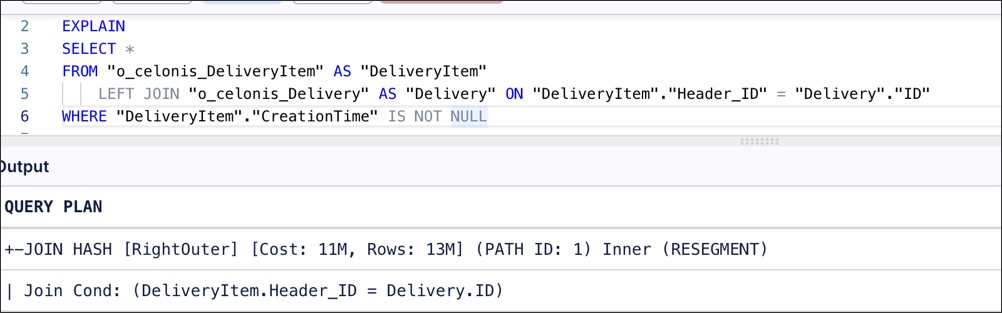 |
However, if you wrap the second table in a subquery that explicitly sorts by Header_ID, the optimizer will detect that both inputs are sorted and switch to a merge join.
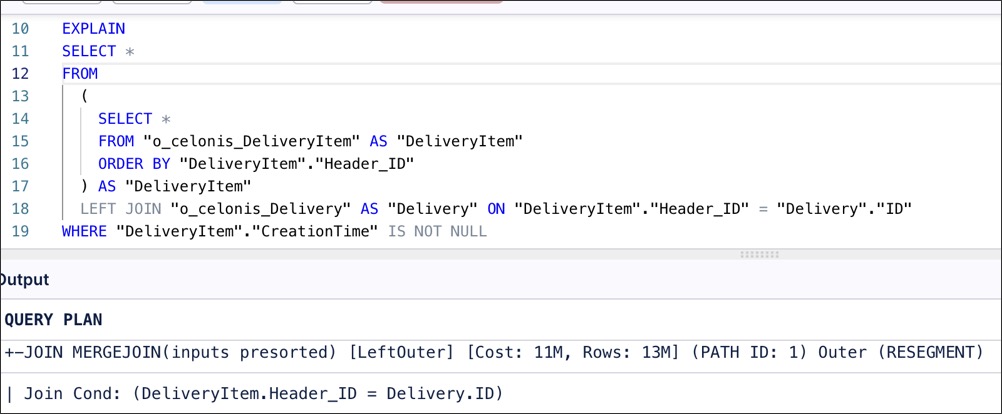 |
Impact under high load
The advantage of using a merge join becomes more pronounced when multiple queries or transformations run concurrently. A large hash join can occupy a significant portion of available memory, slowing down other queries. In contrast, a merge join typically uses less memory for large datasets, resulting in more consistent performance across all running queries.
Alongside the creation of a well-designed temporary table, it is essential to make sure that two tables are adequately joined by the entire join predicates (keys). For example, the MANDT (Client) column is often unduly excluded from join predicates which can have a very negative impact on query performance, ignoring potential MERGE JOIN even when both data sets are properly sorted.
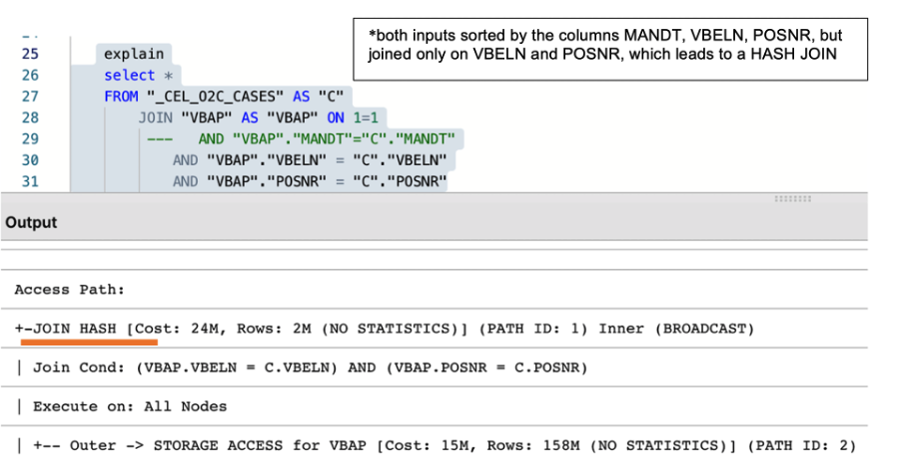 |
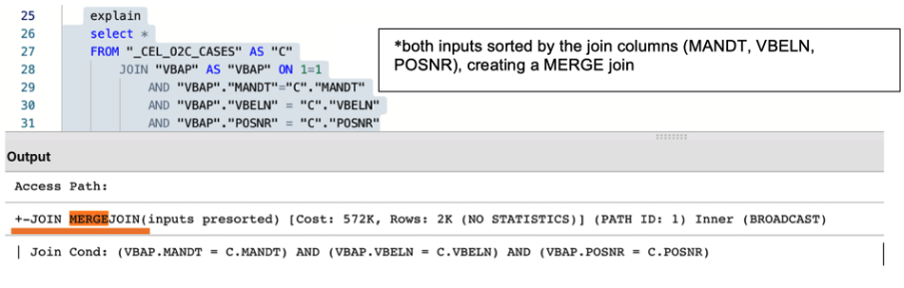 |
Image 3: The impact of using the partial and entire keys when joining two tables
Users often join the same table more than once within one query. Even if the join is identical, it is executed multiple times, leading to increased execution time and risk of error. For example, while creating the Data Model table O2C_VBAP, beside the main case table (VBAP), temporary tables with essentially identical records are often needlessly joined (e.g TMP_VBAP_VBAK, _CEL_O2C_CASES). Usually, the idea behind those redundant joins is filtering or adding some calculated columns (e.g., converted net value).
Best practice:
Evaluate the business needs and only use necessary tables and columns
Revise the flow of logic and consider alternatives to achieve the same (e.g. by using smaller tables such as original (raw tables)
In situations where joining tables with very similar data (e.g. VBAP with TMP_VBAP_VBAK) is unavoidable, make sure that join is ofMERGEkind.
Using views instead of tables might negatively impact transformations and data model load performance.While a temporary table stores the result of the executed query, a view is a stored query statement that is being executed only when invoked.
Each option has advantages and disadvantages and making the right choice highly depends on the table size and structure and query complexity. While replacing a table with a view reduces required storage (APC), it could negatively affect the overall performance and significantly increase total execution time. If the query contains complex logic in terms of types of joins and conditions, the best practice will most likely be the creation of a well-designed temporary table, by fully taking into account previously described recommendations. If the query simply selects all the records from some raw table (e.g. VBAP) or applies simple conditions, a view might be a more reasonable choice. All things considered, one should analyze the specific scenario, ideally, test both approaches and choose the one which is more performant in terms of total transformation and data model load time.
5.1 Implement staging tables for Data model loading
For tables that are being loaded into the Data Model, the best balance in terms of required storage and performance of the entire pipeline is to combine the temporary table (i.e. Staging_table) with a view, as shown on the diagram below.
The statement (example below) that creates the staging table should include all the joins and functions required to calculate or reformat the column values. The staging table should contain only the primary keys and calculated/derived columns.
Subsequently, a data model view is created (e.g. O2C_VBAP), which joins the “raw data” table (i.e. VBAP) with the transformed data table (i.e. O2C_VBAP_STAGING). This approach allows us to achieve better performance without significantly affecting the APC.
Staging table statement example
CREATE TABLE "O2C_VBAP_STAGING" AS
(
SELECT
"VBAP"."MANDT", --key column
"VBAP"."VBELN", --key column
"VBAP"."POSNR", --key column
CAST("VBAP"."ABDAT" AS DATE) AS "TS_ABDAT",
IFNULL("MAKT"."MAKTX",'') AS "MATNR_TEXT",
"VBAP_CURR_TMP"."NETWR_CONVERTED" AS "NETWR_CONVERTED",
"TVRO"."TRAZTD"/240000 AS "ROUTE_IN_DAYS"
FROM "VBAP" AS "VBAP"
INNER JOIN "VBAK" ON 1=1
AND "VBAK"."MANDT" = "VBAP"."MANDT"
AND "VBAK"."VBELN" = "VBAP"."VBELN"
AND "VBAK"."VBTYP" = '<%=orderDocSalesOrders%>'
LEFT JOIN "VBAP_CURR_TMP" AS "VBAP_CURR_TMP" ON 1=1
AND "VBAP"."MANDT" = "VBAP_CURR_TMP"."MANDT"
AND "VBAP"."VBELN" = "VBAP_CURR_TMP"."VBELN"
AND "VBAP"."POSNR" = "VBAP_CURR_TMP"."POSNR"
LEFT JOIN "MAKT" ON 1=1
AND "VBAP"."MANDT" = "MAKT"."MANDT"
AND "VBAP"."MATNR" = "MAKT"."MATNR"
AND "MAKT"."SPRAS" = '<%=primaryLanguageKey%>'
LEFT JOIN "TVRO" AS "TVRO" ON 1=1
AND "VBAP"."MANDT" = "TVRO"."MANDT"
AND "VBAP"."ROUTE" = "TVRO"."ROUTE"
);Data Model view statement example
--In this view the only one join, between the raw table (VBAP) and the staging table (O2C_VBAP_STAGING) is performed. All other joins, required for calculation of the fields should be part of the STAGING_TABLE statement
CREATE VIEW "O2C_VBAP" AS (
SELECT
"VBAP".*,
"VBAP_STAGING"."TS_ABDAT",
"VBAP_STAGING"."MATNR_TEXT",
"VBAP_STAGING"."TS_STDAT",
"VBAP_STAGING"."NETWR_CONVERTED",
"VBAP_STAGING"."ROUTE_IN_DAYS",
FROM "VBAP" AS "VBAP"
INNER JOIN "O2C_VBAP_STAGING" AS VBAP_STAGING ON 1=1
AND "VBAP"."MANDT" = "VBAP_STAGING"."MANDT"
AND "VBAP"."VBELN" = "VBAP_STAGING"."VBELN"
AND "VBAP"."POSNR" = "VBAP_STAGING"."POSNR"
);